Eine der wohl nützlichsten grundlegenden Scripting-Fähigkeiten: Die Inhalte von Tabellen in Variablen speichern, um die einzelnen Daten/spalten separat verarbeiten zu können. Damit ließen sich zum Beispiel Serienbriefe realisieren oder Konfigurationsdateien für Skripte nutzen. Wir zeigen Euch zwei Wege: Ganz einfach über einzelne Variablen und minimal weniger einfach, dafür flexibler, über ein Array.
Datenbasis und Ziel
Die Datenbasis soll hier eine ganz einfache Textdatei sein, in der in jeder Zeile jeweils Vorname Nachname Stadt, also zum Beispiel Peter Petersen Köln und so weiter. Wie genau die einzelnen Daten/Spalten getrennt sind, spielt keine Rolle, hier lassen sich natürlich auch Kommata oder Semikolons nutzen. Leerzeichen sind freilich nicht optimal, weil etwa Klaus Peter nicht als ein Vorname, sondern als Vor- und Nachname gewertet wird. Dafür funktionieren Leerzeichen ohne weitere Angaben, was es für das Verständnis einfacher macht.
Das Ziel ist ebenfalls simpel: Die einzelnen Daten Vorname, Nachname und Stadt sollen zeilenweise separat ausgegeben werden - wie man es für einen Serienbrief nutzen würde.
Die Eingabedatei ist bei beiden Varianten gleich:
peter schmidt lüdenscheid
jochen jochensen halver
tanja müller köln
Und natürlich auch die Ausgabe:
Spalte 1: peter
Spalte 2: schmidt
Spalte 3: lüdenscheid
Spalte 1: jochen
Spalte 2: jochensen
Spalte 3: halver
Spalte 1: tanja
Spalte 2: müller
Spalte 3: köln
Variante 1: Variablen
Das Konzept ist simpel: Die Daten werden zeilenweise eingelesen, unter Angabe eines Namens für jede einzelne Spalte, deren Inhalte dann in gleichnamigen Variablen landen:
cat namen.txt | \
while read spalte1 spalte2 spalte3; do
echo -e \
"\
Spalte 1: $spalte1
Spalte 2: $spalte2
Spalte 3: $spalte3
"
done
Die ganze Arbeit steckt in while read: Die While-Schleife läuft, so lange der read-Befehl eine Zeile zum Lesen bekommt - also bis die übergebenen Zeilen zu Ende sind. spalte1 und so weiter sind dann einfach die beliebigen Namen für die Spalten. echo kann dann die vergebenen Spaltennamen als Variablen, $spalte3 und so weiter, ansprechen.
Statt spalte2 etc. wären hier sicherlich sprechende Namen wie vorname sinnvoller, aber immer weiß man ja auch nicht, wie viele und welche Spalten es gibt. Das ist das Starre an dieser Lösung: Kommen Spalten hinzu, muss der Code angepasst werden.
Variante 2: Array
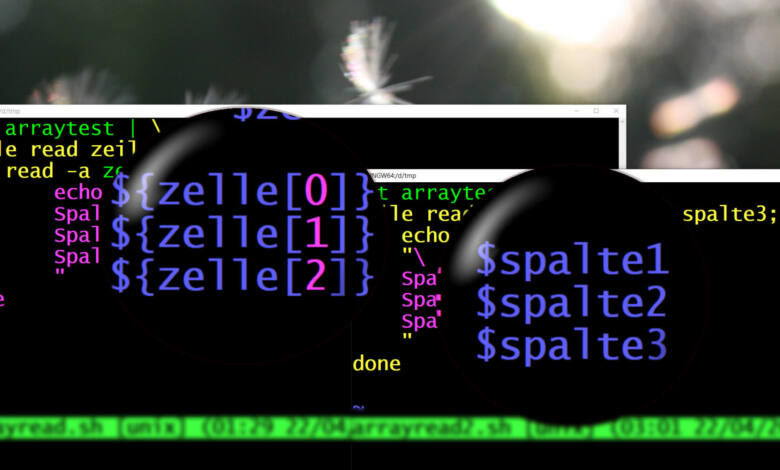
Das Array-Konzept ist im Grunde auch furchtbar trivial: Es kommt fast die gleiche While-Schleife von oben zum Einsatz, allerdings werden keine Namen für Spalten angegeben, stattdessen liest ein zweiter read-Befehl die einzelnen Spalten in ein Array:
cat namen.txt | \
while read zeile; do
read -a spalte <<< "$zeile"
echo -e "\
Spalte 1: ${spalte[0]}
Spalte 2: ${spalte[1]}
Spalte 3: ${spalte[2]}
"
done
Die While-Schleife liest hier zunächst nur die ganze Zeile in eine Variable namens zeile ein. Der zweite read-Befehl liest nun $zeile als Array (-a) ein. echo spricht die Daten dann über ${spalte[0]} an, also "Erstes Datum im Array spalte" (Arrays fangen bei 0 an zu zählen.).
In der ersten Lösung gab es also fix vergebene Variablen für Spalten ($spalte12), in der zweiten Variante werden alle Spalten in ein Array eingelesen und dann durchnummeriert angesprochen (${spalte[11]}). Für übersichtliche Dateien mit bekannten Daten ist die erste Variante recht naheliegend, zumal die Variablen einfach hübsch benannt werden können. Für große unbekannte Datenbestände, die zum Beispiel aufbereitet werden sollen, ist die Array-Variante besser - zumal sich das noch ausbauen lässt. Man könnte zum Beispiel jede Zeile in ein eigenes Array packen, um später noch auf einzelne Daten zugreifen zu können.
Mittlerweile kann Bash auch mehrdimensionale Arrays basteln, aber im Alltag dürften die beiden hier vorgestellten Methoden meist genügen.
Mehr zur Kommandozeile hier bei uns und auch dort: