Tag-Clouds kennt Ihr freilich von etlichen Blogs, sozialen Netzwerken und und und. Aber Ihr könnt Word Clouds auch manuell aus beliebigen Texten basteln - beispielsweise aus Artikeln oder Büchern. Das Coole daran: Man sieht auf einen Blick worum es geht - ein Bild sagt mehr als tausend Worte? Dann schaut Euch erstmal ein Bild aus tausend Worten an! Zwei Möglichkeiten möchten wir Euch vorstellen: Die einfache Möglichkeit mit kostenloser Desktop-Software von IBM und die Variante mit besonders schickem Ergebnis (das hier auch als Einstiegsbild dient) via Browser.
Variante 1: IBM Word Cloud - einfach
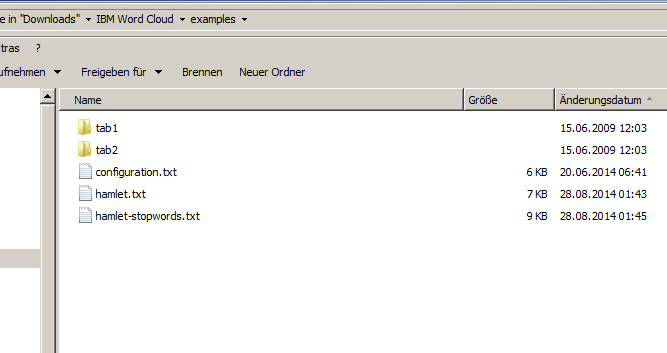
Natürlich könntet Ihr einfach einen beliebigen Text, etwa diesen Ebola-Artikel von SPON, in einen x-beliebigen Word-Cloud-Generator werfen. Aber was glaubt Ihr wird das häufigste und insofern am prominentesten platzierte Wort? Vermutlich "und" oder "die" oder ähnliches. Derlei uninteressante Wörter nennen sich Stoppwörter und die müssen aus dem Text entfernt werden. IBMs Lösung bietet zwar nur ein Beispiel-Skript und keinerlei GUI, aber wennn Ihr es einfach haben wollt, so geht's: Besorgt Euch den IBM Word Cloud Generator, entpackt ihn und nutzt das Beispiel-Skript im "examples"-Ordner. Hier müsst Ihr lediglich Euren Text in die hamlet.txt kopieren und eine Liste von Stoppwörtern in die hamlet-stopwords.txt. Dann startet Ihr das Skript run-example.bat und schon wird eine Word Cloud ausgespuckt. Anpassungen nehmt Ihr über die configuration.txt vor, müsst Ihr aber nicht. Das Ergebnis ist nicht der große Wurf, aber es geht schnell und natürlich könnt Ihr den Workflow anpassen.

Variante 2: Beliebige Generatoren - schick
Es gibt deutlich schickere, kostenlose Online-Dienste für Word Clouds, beispielsweise von Jason Davies. Dort genügt es, einen Link zu einem Artikel oder einen Text einzufügen und die Optionen lassen sich auch direkt auf der Website anpassen. Leider gibt es hier keine Stoppwörter-Option. Also müsst Ihr diese manuell entfernen, was total simpel ist, auch wenn es - ja ich weiß, jetzt wird's nerdig - mit der Kommandozeile gemacht wird, und zwar unter Linux. Angenommen, Ihr habt einen Artikel in der Datei artikel.txt und Stoppwörter in der Datei stopwords.txt, dann lautet der Befehl zum Bereinigen:
fmt -0 artikel.txt | grep -w -i -v -f stopwords.txt
Was passiert hier? Das Tool fmt erstellt neue Absätze nach n Zeichen, wobei mindestens ein Wort pro Absatz existiert. Mit der Option "-0" erstellt fmt also eine reine Wortliste mit einem Wort je Zeile. Aus
Hallo Welt
würde also
Hallo
Welt
Die grep-Anweisung sucht nun alle Zeilen (darum die Umwandlung mit fmt), die den nachfolgenden Optionen entsprechen: Mit -w werden nur ganze Wörter gesucht, -v dreht das Ergebnis um, sodass alle Zeilen gefunden werden, die eben nicht dem gesuchten Muster entsprechen, -i ignoriert Groß-/Kleinschreibung und mit -f wird das gesuchte Muster (hier also die Stoppwörter) aus der Datei stopwords.txt gelesen. Ja, klingt doof, hier also nochmal in Menschensprache: fmt macht aus Fließtext eine Wortliste und grep gibt nur die Wörter aus, die nicht in der Datei stopwords.txt vorkommen. Um die Datei dann in einen neue zu schreiben, vervollständigt Ihr etwa mit
fmt -0 artikel.txt | grep -w -i -v -f stopwords.txt > bereinigter-artikel.txt
Den Text aus "bereinigter-artikel.txt" könnt Ihr dann einfach in das Formular pasten und schon kommt eine Word Cloud heraus, die nur "gehaltvolle" Wörter nutzt.
Übrigens: Mit Tools wie fmt und grep, egal, wie obskur sie für Otto Normal-Windows-Nutzer erscheinen mögen, lassen sich viele Aufgaben viel schneller erledigen, als mit GUI-Programmen unter Windows - in der vermutlich übernächsten c't Hier in der c't findet Ihr rund fünf Seiten zum Thema Textverarbeitung auf der Kommandozeile von mir.
Und hier noch der Wandel des Texts im Bild:
Original
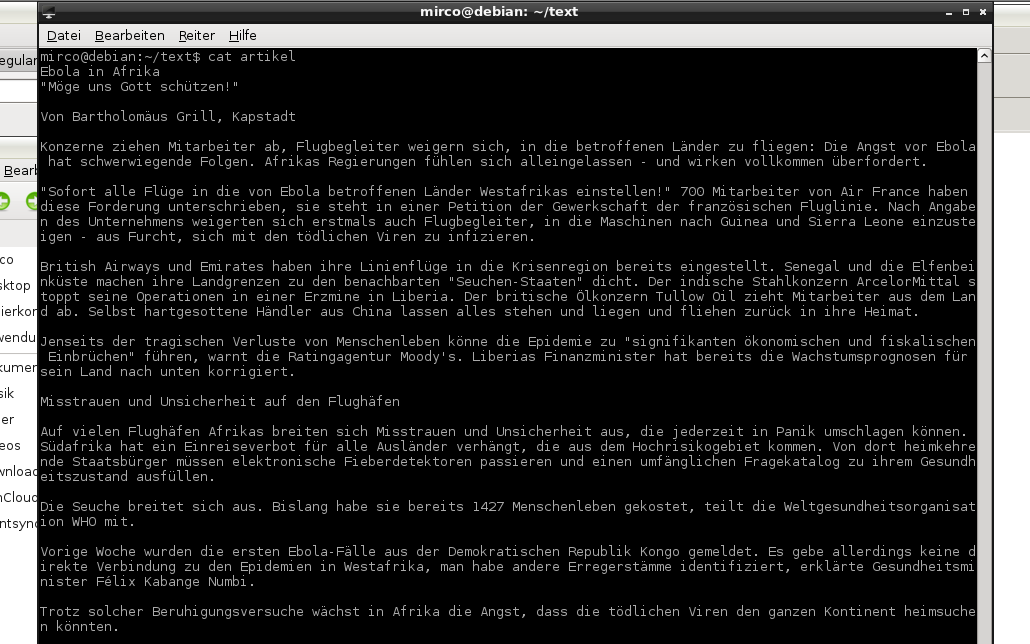
Wortliste
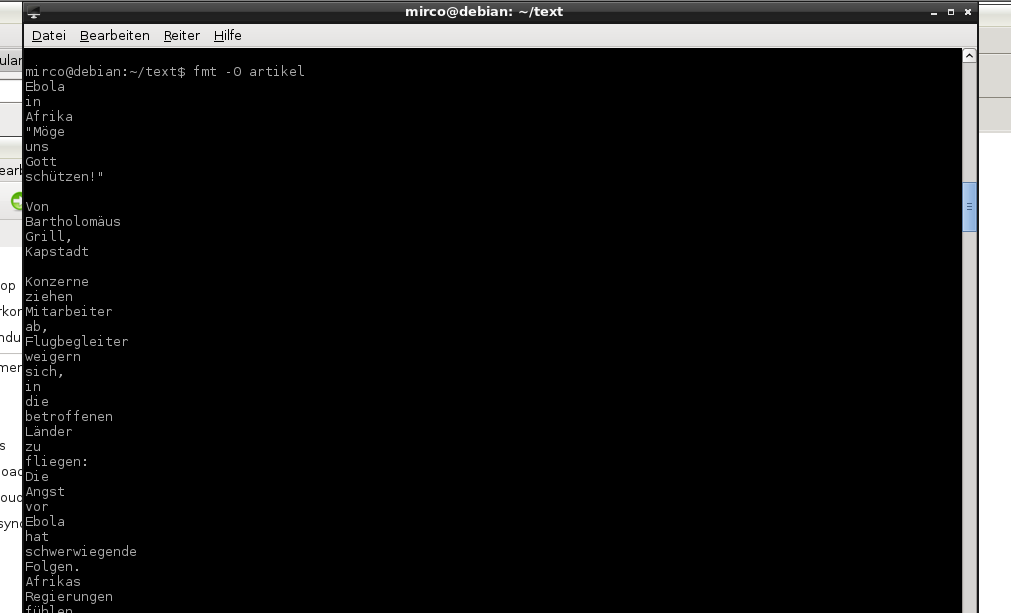
Wortliste ohne Stoppwörter
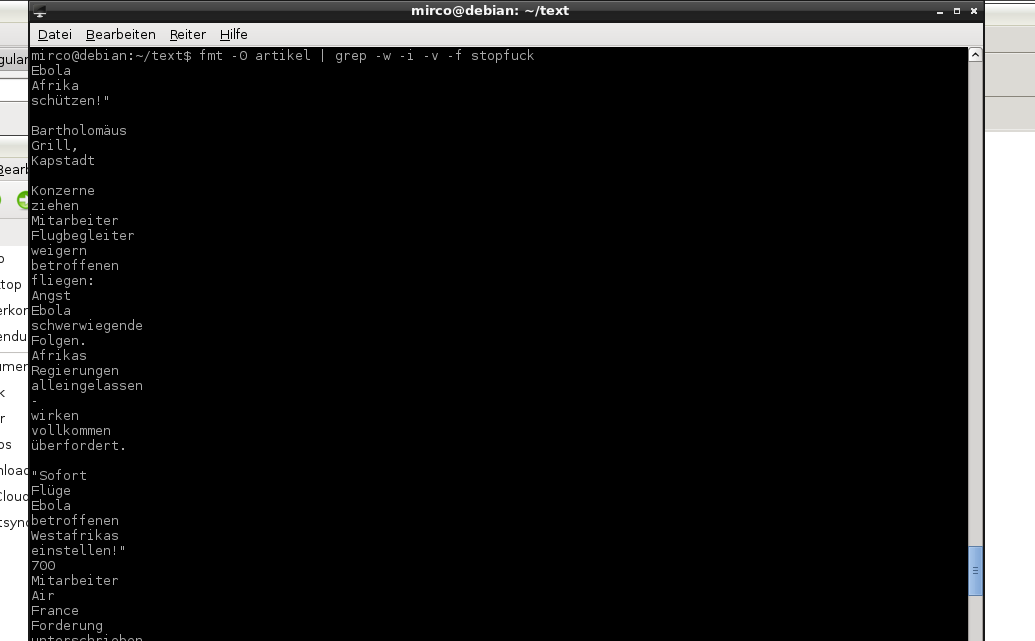
Worliste einfügen
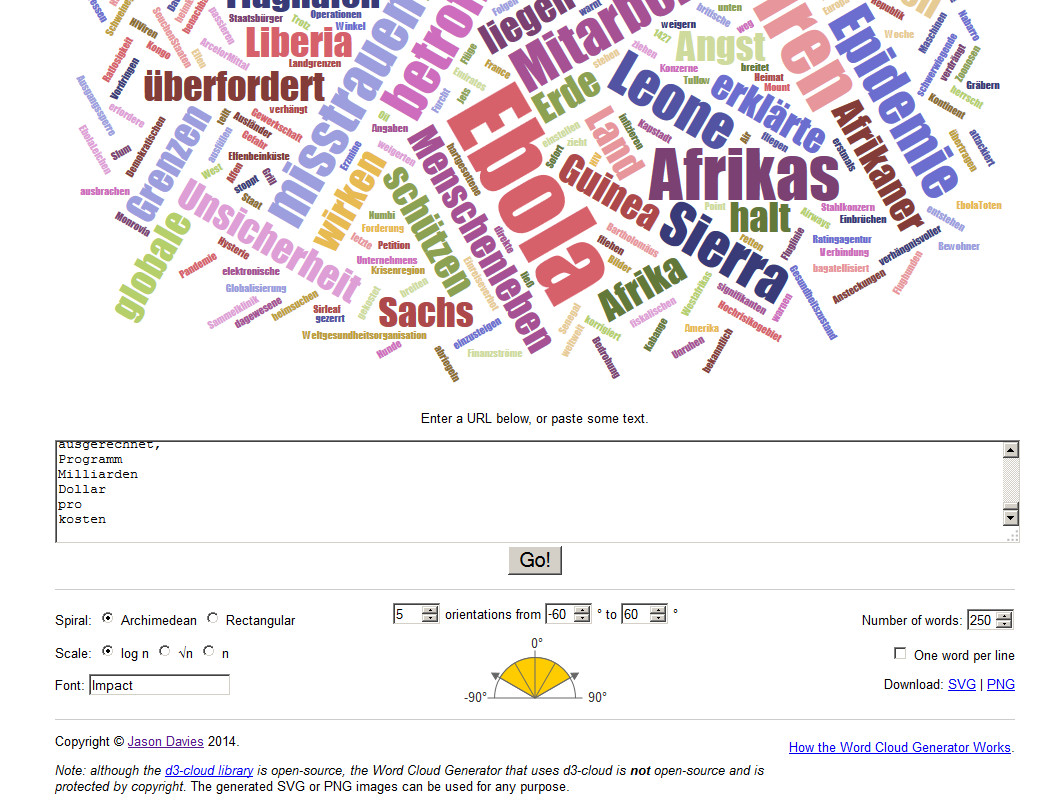
Die fertige Wordcloud