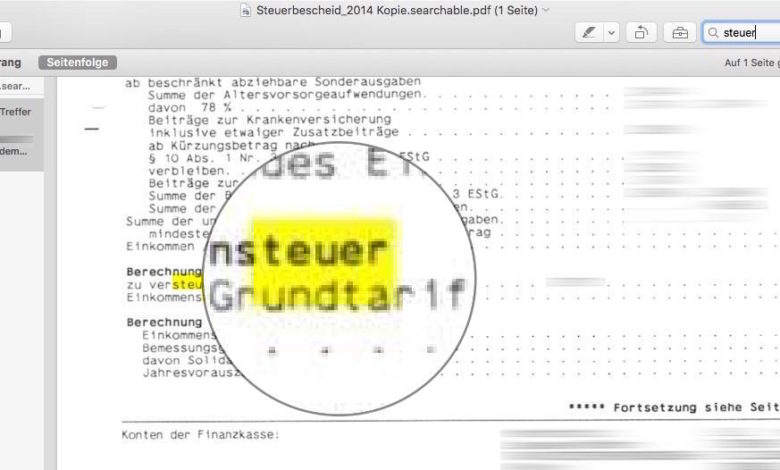
Wenn man ein Dokument scannt, gibt es dabei in aller Regel ein Problem: Das PDF ist zwar eine PDF-Datei, allerdings verhält diese sich eher wie ein Bild! Der enthaltene Text lässt sich nicht durchsuchen. Das Aufspüren bestimmter Dateien mit einer Desktop-Suche wie Siri, Spotlight oder Cortana wird so zur höllischen Aufgabe. Das muss nicht sein: Fügt doch einfach nachträglich eine OCR-Texterkennung ein.
OCR Texterkennung in PDFs packen
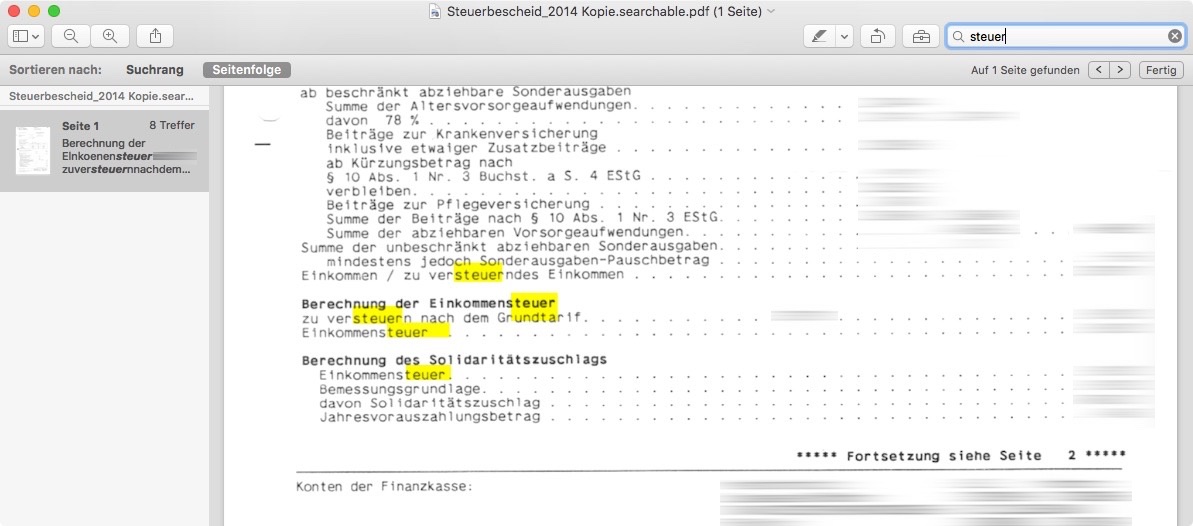
Möglich wird das an PC und Mac mit der kostenlosen App PDF OCR X, mit deren Hilfe Ihr bereits vorhandene PDFs nachträglich in durchsuchbare PDFs verwandelt. Die gibt's für Mac-Nutzer auch gratis im AppStore. Die Bedienung ist denkbar einfach: Zieht Euer Dokument ins PDF-OCR-Fenster, wählt als "Output-Setting" "Searchable PDF" und wählt ein Ausgabeverzeichnis. Anschließend müsst Ihr nur noch auf "Convert" klicken: PDF OCR X legt eine Kopie der ursprünglichen PDF-Datei an, deren Text sich durchsuchen lässt. Wichtig ist nur, dass Ihr das deutsche Sprachpaket im Programm installiert habt ("Install more languages").
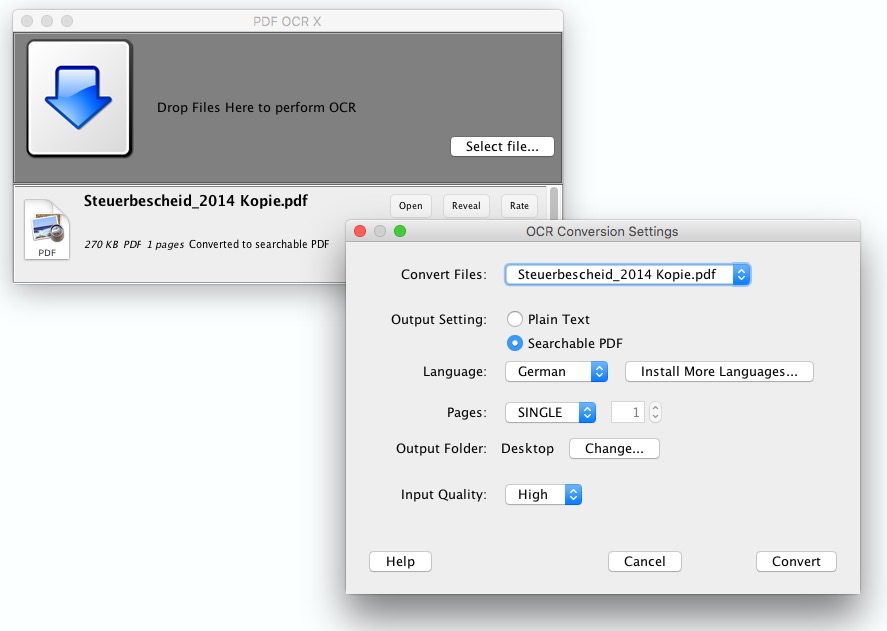
Batch-Verarbeitung und automatisches Überschreiben
Natürlich kann der PDF-Converter auch mehrere Dateien hintereinander bearbeiten: Zieht dafür einfach mehrere PDFs ins Programmfenster. Ebenfalls praktisch: Das Tool kann auch direkt die Originaldatei durch eine durchsuchbare Variante ersetzen, indem Ihr in den Einstellungen "Overwrite PDF" auswählt. Die Option ist allerdings mit Vorsicht zu genießen, weshalb Ihr besser immer noch eine Kopie der Originaldatei vorhaltet. Ansonsten ist das Tool aber eine ebenso einfache wie praktische Möglichkeit, alte PDF-Dateien mit einer Texterkennung auszustatten und damit für den Computer lesbar und leichter auffindbar zu machen.


Wenn ich PDF OCR X runterladen will, werde ich nach meinen Kontodaten gefragt. Ich hatte verstanden, dass das Tool kostenlos ist. Für mich ein Widerspruch. Ich habe erst mal abgebrochen.
Hallo Stefan,
bei mir lädt die „Community Edition“ – und das ist auch die, die wir im Artikel verwendet haben – nach wie vor kostenlos. Ich denke, Du hast vermutlich die „Enterprise-Edition“ ausgewählt? Übrigens gibt es das Tool auch im Mac-AppStore: https://itunes.apple.com/de/app/pdf-ocr-x-community-edition/id571442933?mt=12
Wenn das OCR’en einmal erledigt ist, lassen sich die PDFs auch per Batch in Textdateien umwandeln – hier die Linux-Anleitung, aber das Tool gibt es auch für Mac, dürfte (nahezu) genauso funktionieren.
Braucht man nicht, kann PDF-OCR-X auch.