In diesem Artikel werdet Ihr erfahren, wie Git grundsätzlich aus Nutzersicht funktioniert und wie Ihr mit den Grundfunktionen arbeiten könnt. Kurz (nun ...), einfach und ohne Fachsprech. Wie Git intern funktioniert und was es alles Tolles in größeren Projekten kann, bleibt außen vor. Erfahrungsgemäß ist es anfangs schon lästig genug, normale, simple Workflows wie Dokument herunterladen, ändern, speichern, hochladen mit diesem ollen Terminal-Monster zu erledigen - nicht wahr? ;) Schon die vielen neuen Begriffe nerven - in Git hieße der Workflow: "Index pullen, ändern, committen, pushen" und würde exakt das gleiche bedeuten. Naja, fast exakt.
Disclaimer: Wir distanzieren uns von der Formulierung "nur das Nötigste", so lang kann nichts Nötiges sein ... Sorry, es ist länger geworden als geplant und dennoch an manchen Stellen so vereinfacht, dass manch ein Git-Freak wohl stöhnen dürfte. Vielleicht sind rund 25.000 Zeichen einfach nötig, um Git ohne jegliches Vorwissen soweit zu verstehen, dass sich damit rund 80 Prozent des Git-Alltags bewerkstelligen lassen. Bei Fragen, fragen!
Was ist überhaupt Git? Und GitHub?
Nur ganz kurz, vermutlich wisst Ihr das eh schon: Git ist ein Version Control System (VCS), also ein Programm, mit dem verschiedene Versionen von Projekten erstellt und verwaltet werden können. Im Wesentlichen wird das für die Software-Entwicklung genutzt, aber auch zur Pflege von Webseiten oder der Software-Dokumentation.
Git hat dabei einige wirklich tolle Features: Alle Änderungen sind transparent, alles ist offline verfügbar, man kann über einen Server mit anderen zusammenarbeiten, es ist kaum möglich, Daten zu verlieren, es gibt etliche Funktionen rund um die Automatisierung, Mechanismen für Konfliktlösungen (wenn zwei Menschen eine Datei unterschiedlich bearbeiten), eine riesige Infrastruktur von Tools, Skripten, Hosting-Angeboten und so weiter.
GitHub ist genau das, was der Name sagt: Ein Hub für Git, also eine Online-Plattform, über die per Git gemeinsam an Projekten gearbeitet werden kann. Ein Großteil aller Open-Source-Projekte läuft über GitHub, aber auch viele proprietäre Produkte werden dort gepflegt, dann eben in geschlossenen Bereichen. GitHub ermöglicht es auch, viele der Git-Operationen direkt online im Browser über die Weboberfläche zu erledigen und fügt weitere Features hinzu.
Im Folgenden geht es aber nicht um GitHub und auch nicht um die vielen tollen Features, sondern um die Basics: Wie funktioniert Git analog zu einem normalen Office-Workflow? Mal als Vergleich:
Office-Workflow: Normalerweise werdet Ihr eine Datei im Explorer (also unter Windows zumindest ...) in einem Projektordner erstellen, dann mit beispielsweise Word oder Writer bearbeiten und speichern und dann vielleicht mit Dropbox hochladen/synchronisieren. Extra: In Word & Co. könnt Ihr den "Bearbeitungsmodus" aktivieren, um später einzelne Änderungen im Dokument nachvollziehen zu können - mit Datum und Urheber.
Git-Workflow: Auch hier könnt Ihr eine Datei im Explorer erstellen und mit Word bearbeiten - das sind nicht die Aufgaben von Git. Git übernimmt aber die Aufgaben von Dropbox, also das hoch- und runterladen, das Synchronisieren. Und es zeichnet ähnlich wie Word die Bearbeitungshistorie auf; natürlich für alle Änderungen aller Beitragenden auf allen Rechnern und unauslöschlich für immer!
Grundsätzliche Funktionsweise
Mit den Interna möchten wir Euch hier verschonen, über den Index, Marker, HEAD, Merging-Strategien, Rebasing, Cherry-Picking etc. könnt Ihr Euch auch später noch beschäftigen - es gibt tolle Videos dazu, so mit Bauklötzchen und so ;)
Ein Git-Projekt nennt sich Repository, was - aus Nutzersicht - im Grunde zunächst nichts weiter ist als eine Ordnerstruktur mit Dateien darin. Allerdings gehören nicht automatisch alle Dateien in der Ordnerstruktur zum Repository, Ihr müsst sie manuell hinzufügen. Dabei sieht Git durchaus alle Dateien in den Ordnern und meckert dann entsprechend, wenn Dateien vorliegen, die nicht von Git überwacht werden. Wenn man etwas Hilfsdateien oder Dateien mit Passwörtern nicht mit anderen Teilen möchte, kann man sie auch explizit ignorieren. Merke: Git überwacht Dateien, die dem Repository hinzugefügt werden - mit dem Befehl git add.
Wenn ihr nun Änderungen an einer Datei vornehmt, speichert Ihr sie lokal so wie immer mit dem Editor Eurer Wahl. Git erkennt darauf hin, dass sich eine Datei geändert hat. In Git wird nun die Änderung an sich, also der Unterschied zwischen dem ursprünglichen Datei-Inhalt und der aktuellen Version, gespeichert - der so genannte Commit (Beitrag). Das Schöne: Änderungen lassen sich auch 40 Änderungen später wieder rückgängig machen. Beispiel: Ihr ändert in einem Dokument die Schreibweise "Web-Browser" in "Webbrowser" und wollt diese Änderung wieder rückgängig machen. Dann müsst Ihr lediglich den entsprechenden Commit wieder zurücknehmen. Oder Ihr könntet diese Änderung in andere Versionen des Dokuments übernehmen, aber dazu später mehr. Merke: Git speichert Änderungen in Commits - über den Befehl git commit.
Und nun zum namensgebenden Teil, den Versionen: Bei der Software-Entwicklung gibt es nach einer Zeit meist mehrere Versionen, die bis zu einem bestimmten Punkt natürlich identisch sind - Version 1.5 besteht aus der Version 1.0 plus weiterer Änderungen/Commits. Versionen lassen sich in sogenannten Branches (Ästen) verwalten: Standardmäßig arbeitet Ihr in Git mit einem Standard-Branch namens master. Wenn Ihr nun mit der Arbeit an einer Version 1.5 beginnen wollt, könntet Ihr einen zweiten Branch namens beispielsweise "version_1.5" erstellen. Zunächst ist dieser eine 1:1-Kopie vom master-Branch und Ihr könnt an der neuen Version arbeiten, ohne Eure Version 1.0 zu verändern. Das Tolle: Wenn Ihr in Version 1.5 etwas ändert, das auch für die Version 1.0 relevant ist, beispielsweise eine URL aktualisiert, könnt Ihr diese Änderung, diesen Commit, einfach in Version 1.0 übernehmen. Merke: Git verwaltet Versionen in Branches/Ästen - zu erstellen mit dem Befehl git branch.
Nebenbei: In der Entwicklungspraxis werden auch einzelne Features oft in separaten Branches entwickelt - sagen wir mal ein neues Dark-Theme für das Produkt. Wenn das Dark-Theme fertig entwickelt und getestet ist, kann man dann den kompletten Branch (also letztlich eine Reihe von Commits) in den Haupt-Branch übernehmen, und natürlich auch in weitere Branches, etwa von Demo- oder Legacy-Versionen.
Es gibt aber noch eine zweite Ebene der Versionierung: Eine aktuelle Datei in Eurer Ordnerstruktur ist das Ergebnis aller Commits. Und Ihr könnt Git jederzeit anweisen: "Git, gib mir die Datei in der Version vor den letzten 20 Änderungen." Versucht das mal mit Word ;) Egal, ob Ihr eine alte Dateiversion aus dem aktuellen Branch speichern oder zu einem anderen Branch wechseln wollt, der ziemlich intuitiv klingende Befehl dazu ist schlicht checkout.
Nebenbei zu den Branches: Stellt Euch vor, Ihr habt ein Repository mit einem Branch für englisch- und einem für deutschsprachige Dateien. Im Dateimanager seht Ihr immer nur die Dateien des aktuell gewählten Astes! Darum schimpft sich die eigentliche Ordnerstruktur mit aktuellen Dateiversionen auch Working Tree. Beispiel: Ihr habt im Branch de-branch eine Datei C:\git\mein-repo\deutsch.txt im Explorer. Wechselt Ihr dann auf den Branch en-branch, seht Ihr stattdessen nur noch die Datei C:\git\mein-repo\english.txt. Das macht - hoffentlich - nochmal deutlich, dass Git im Grunde keine Dateien verwaltet, sondern lediglich Änderungslisten. Mal als popelige Mathe-Analogie ausgedrückt, hier zwei Ausrücke, die exakt dasselbe meinen: 9 und 3+3+3 liefern eindeutig ein identisches Ergebnis - nur, dass bei der zweiten (Git-)Variante klar ist, wie sich das Ergebnis genau zusammensetzt. Merke: Bestimmte Dateiversionen (und Äste) lassen sich aus Git heraus aufrufen - mit dem Befehl git checkout.
Jetzt zum Dropbox-Part, dem Synchronisieren: Git funktioniert komplett offline, einen Git-Server benötigt Ihr nur zum Teilen beziehungsweise, um ein Backup in der Cloud zu haben. Viele Webhoster bieten auch eigene Git-Server an, alternativ könnt Ihr GitHub, GitLab, Bitbucket oder sonst einen Cloud-Service nehmen. Wenn Ihr Eure Änderungen/Commits also teilen beziehungsweise online backuppen wollt, müsst Ihr sie entsprechend hoch- und runterladen. Bei Dropbox genügt es, Dateien in einen bestimmten Ordner zu legen, bei Git müsst Ihr das manuell erledigen - in Git nennt sich das Pullen (Download) und Pushen (Upload). Merke: Sychnronisation läuft in Git über separate Up- und Downloads - über die Befehle pull und push.
Das soll nun zur Grundlagentheorie genügen - trotz Vereinfachungen ist das für den Anfang ja schon nicht ganz trivial. Aber keine Sorge, gleich wird das alles in der Praxis durchgespielt, danach sollte alles sitzen. Doch zuvor ...
Was wir übersprungen haben ...
Zum einen gibt es natürlich noch massenhaft weitere Möglichkeiten, zum anderen haben wir ausgelassen, wie Git intern arbeitet - das ist nämlich nicht ganz ohne. Git bietet Werkzeuge für die Lösung von Konflikten (wenn etwa zwei Menschen unterschiedliche Änderungen an derselben Datei vorgenommen haben), für das Übernehmen einzelner Commits in andere Branches, für das Verschmelzen von Branches auf unterschiedliche Weisen, zum Zwischenspeichern von Änderungen, zum Einsehen der Änderungsgeschichte oder Versionsunterschieden und so weiter. Man kann Git problemlos über Jahre nutzen und noch dazulernen!
Auch die Interna sind nicht ganz ohne, da gibt es aber schöne Videos, wo Git-Nerds mit Hilfe von Bauklötzchen in die Tiefe gehen. Ein Aspekt ist für das Verständnis aber besonders wichtig: Der HEAD. Mit HEAD ist - vereinfacht - einfach ein Zeiger gemeint, der auf die aktuelle Version/den aktuellen Branch zeigt. HEAD könnte also zum Beispiel auf "Commit 123456 auf Branch XY" zeigen - und die entsprechenden Dateien des Branches bis zu diesem Commit seht Ihr dann im Dateimanager. (HEAD hat am Ende noch einen Gastauftritt ;) )
So, nun aber endlich Praxis.
1. Repo erstellen oder herunterladen
Ob Windows oder Linux oder (vermutlich) auch macOS, die Arbeit mit Git ist immer gleich. Git for Windows bringt erfreulicherweise auch die Bash mit, den Standard-Terminal der meisten Linuxe. Darin stehen dann alle hier genutzten Befehle abseits von Git ebenfalls zur Verfügung (etwa cd zum Navigieren oder touch zum Anlegen von Dateien). Pfade innerhalb der Bash schreiben sich etwas anders als unter Windows üblich, nämlich zum Beispiel /c/arbeit/git statt C:\arbeit\git.
Zu Beginn muss natürlich erstmal ein Repository (kurz Repo) her. Das könnt Ihr entweder selbst mit
cd /c/arbeit/git/mein-repo
git init
erstellen (init-iieren) oder ein bestehendes per
cd /c/arbeit/git
git clone https://github.com/Tutonaut/tutonaut-repo
herunterladen. Die Befehle clone und init braucht Ihr nur dieses eine Mal.
Tipp: Registriert Euch bei GitHub, das ist kostenlos und Ihr könnt auch hoch- und runterladen. Am besten legt Ihr Euch dann ein Repo über die Weboberfläche an und holt es Euch dann per clone-Befehl auf den Rechner. Oder Ihr "forkt" ein bestehendes Repo auf GitHub: Darüber wird das Repo auf Euren Account kopiert und Ihr könntet zum Beispiel eine eigene Version davon erstellen - dank offener Lizenzierung ist das völlig problemlos. Den Fork-Button findet Ihr oben rechts auf der Repo-Seite - nach dem Fork hat Eure Kopie natürlich eine eigene URL.
Für dieses Tutorial gehen wir von einem Repo aus, das online bereits existiert - im Zweifel forkt und klont einfach unser Test-Repo.
2. Dateien hinzufügen, Änderungen speichern
Mit git status könnt Ihr jederzeit den Status Eures Repos einsehen. Im Folgenden zeigen wir nach den einzelnen Schritten in Klammern jeweils, was status sinngemäß ausgibt.
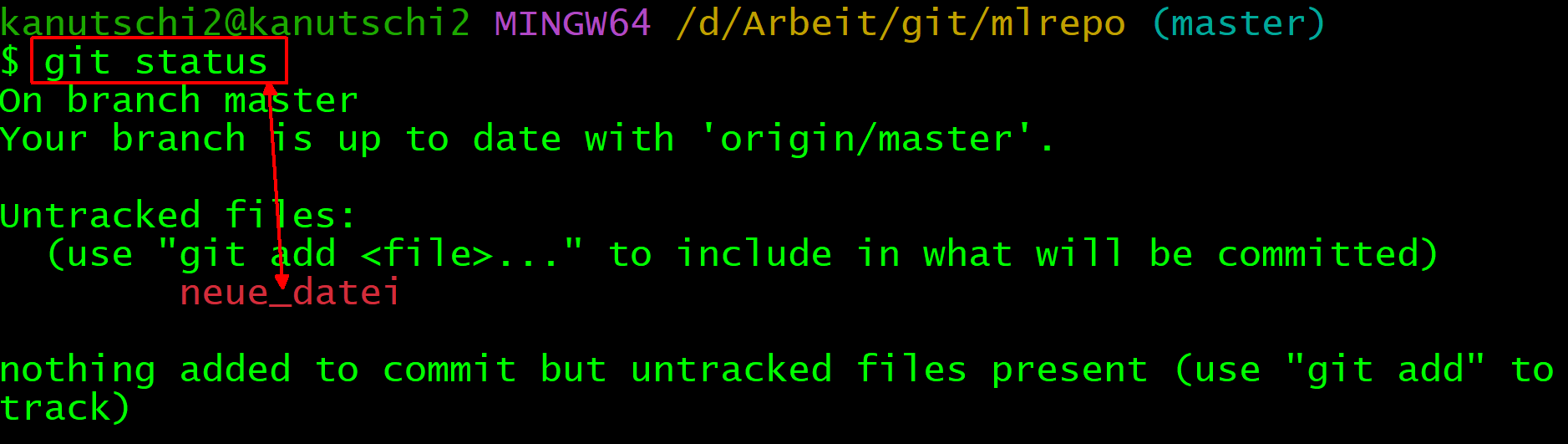
Ihr befindet Euch nun also in Eurem tendenziell leeren Repo (C:\Arbeit\git\mein-repo). Nun könnt eine erste Datei anlegen und zur Git-Überwachung hinzufügen:
touch foobar.txt --> status: Nicht überwachte Datei gefunden
git add foobar.txt --> status: Änderungen gefunden, die committet werden können
Oder wenn Ihr alle Dateien im Ordner hinzufügen wollt:
git add .
Nun muss dieser aktuelle Zustand gespeichert werden - via Commit:
git commit -m "Informationen ..." foobar.txt --> status: Working Tree ist sauber, alles ist gespeichert
Oder zum Speichern aller überwachter Dateien:
git commit -am "40 Dateien hinzugefügt oder so ..."
Hier steht das "-a" steht hier einfach für "all". Das -m steht für Message: Jeder Commit wird mit einer Nachricht versehen, die kurz beschreiben sollte, was passiert ist. Ihr könnt hier schreiben was Ihr wollt, aber es lohnt sich, die Nachrichten aussagekräftig zu gestalten! Es gibt sogar Konventionen für den Aufbau dieser Nachrichten aus denen dann zum Beispiel automatisch Change-Logs erstellt werden können. Bei Dev-Insider habe ich mehr dazu geschrieben (Link folgt, Artikel ist noch nicht online).
Wenn Ihr an dieser Stelle den Status aufruft, bekommt Ihr sogar zwei Informationen:
git status
--> Working Tree ist sauber, alles ist gespeichert
--> Your branch is ahead of 'origin/master' by 1 commit.
Die zweite Zeile meint: Euer lokaler Branch auf Eurem Rechner ist einen Commit weiter/aktueller als der zugehörige Branch auf dem Server - wobei hier der Branch auf den Namen master hört (Standardname). Mit origin ist die Herkunft des lokalen Branches gemeint, also letztlich der Git-Server. Diese Information zeigt Euch auch der Log von Git (git log):
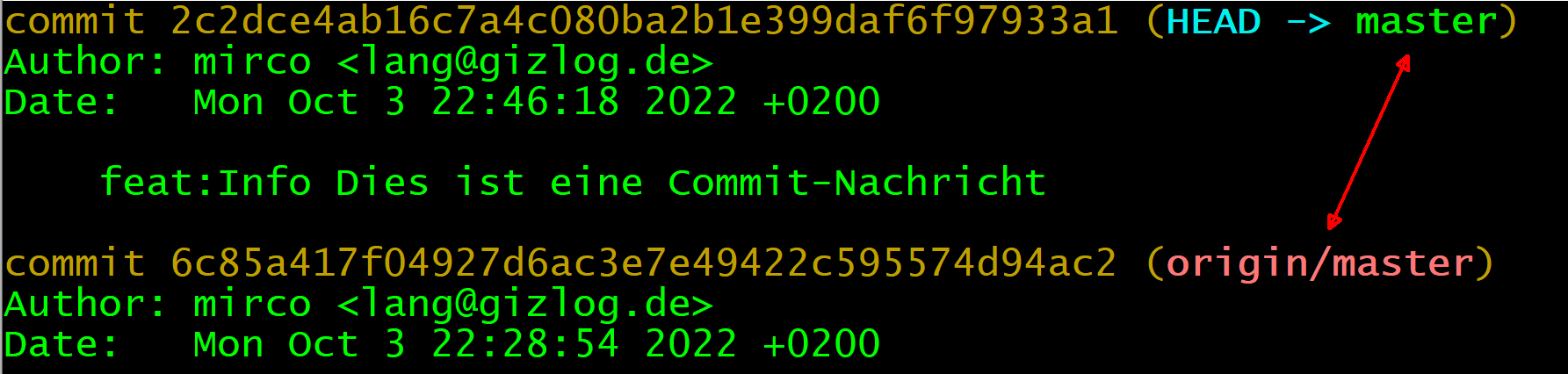
3. Dateien hoch-/runterladen
Nun habt Ihr den Zustand der Datei lokal in Git festgehalten und könnt sie hochladen, um den Server-Branch (origin/master) auf den aktuellen Stand zu bringen:
git push --> status: Up to date mit origin/master; nichts zu committen
Nach dem Befehl müsst Ihr zunächst Eure Login-Daten für den Server/das entfernte Repo eintragen (das lässt sich später auch automatisieren, aber das ist wieder ein anderes Thema).
Zu Testzwecken könntet Ihr nun mal direkt im Browser auf GitHub die eben hochgeladene Datei verändern - dann ist logischerweise der Server einen Commit voraus und Ihr müsstet zum Synchronisieren diesmal herunterladen:
git pull
zieht die Änderungen und aktualisiert den Arbeitsbereich - Server und lokaler Rechner sind wieder synchron.
Pull funktioniert allerdings nur, wenn Ihr lokal alle Änderungen als Commit gespeichert habt!
Ausblick: Genau an dieser Stelle kann es zu Konflikten kommen, wenn Ihr beispielsweise auf GitHub direkt die Zeile 1 einer überwachten Datei in "foo" und offline in derselben Datei in "bar" geändert habt. Git kann natürlich nicht wissen, ob Ihr in der ersten Zeile nun lieber foo oder bar oder vielleicht beides oder was ganz anderes stehen haben wollt. Diese Art von Konflikten gibt es bei Dropbox & Co. freilich auch. Wie die Konfliktlösung abläuft, ist abermals ein anderes Thema.
4. Versionen, Äste, Logs
Die wichtigsten Arbeitsabläufe zum Speichern und Syncen von Dateien kennt Ihr nun. Gegen Ende gibt es jetzt noch ein paar Befehle zu Ästen und Versionen - auch diese Dinge tauchen relativ früh in Eurem Git-Leben auf, zumindest, wenn das Projekt komplex wird oder schlicht andere Menschen mitarbeiten - oder Ihr selbst von diversen Orten aus werkelt.
Der Standard-Branch heißt meistens master (oder main) und in der Git-Bash-Version für Windows steht der Name des aktuellen Asts auch direkt im Prompt.

Wenn Ihr nun einen zweiten Branch haben wollt, namens mein_branch etwa, dann legt Ihr diesen so an:
git branch mein_branch
Um zu diesem Ast zu wechseln:
git checkout mein_branch
Wie oben bereits erwähnt, ist checkout das Kommando, um zu einem Branch zu wechseln - oder zu einer bestimmten Version einer Datei im aktuellen Branch. Dazu benötigt Ihr den Commit-Hash, die eindeutige ID des Commits, bis zu dem zurückgesprungen werden soll. Ruft dazu den Log auf:
git log
zeigt die zurückliegenden Commits samt einer langen Zeichenkette, dem Hash.

Kopiert den Hash des gewünschten Commits (hier 12345) und führt dann folgenden Befehl aus, um beispielsweise die Datei foo.txt auf den Stand des gewünschten Commits zu bringen. Tipp: Doppelklickt den Hash zum Kopieren, der mittlere Maus-Button fügt dann ein:
git checkout 12345 foo.txt
Im Working Tree, also dem Dateisystem, seht Ihr nun die Datei foo.txt auf dem Stand des Commits 12345 - alle danach gemachten Änderungen sind aus der Datei verschwunden. Allerdings wurde hier nicht wie bei Word oder so irgendwas "rückgängig" gemacht! Es handelt sich um eine weitere Änderung, Ihr müsst also wieder committen. Folglich sind auch die zurückgenommen Änderungen noch vorhanden und können jederzeit über ihre Commit-Hashes wiederhergestellt werden.
Wenn Ihr hingegen wirklich etwas rückgängig machen wollt, sagen wir die letzten zwei Commits komplett zurücknehmen, dann wird die Grenze überschritten, bis zu der man Git (ungefähr ...) nutzen kann, ohne sich intensiver mit den Interna beschäftigen zu müssen. Und damit auch den Fokus dieses Artikels. Ist schon lang genug der Käse ;)
Aber Ihr erinnert Euch an den oben erwähnten Zeiger namens HEAD? Der kam nicht ohne Grund im Kapitel zu übersprungenen Grundlagen vor. Zur Erinnerung: Der Zeiger HEAD zeigt auf den aktuellen Branch und dort auf den aktuellsten Commit - also quasi das Hier und Jetzt der Dateien im Working Tree. Wenn Ihr nun die letzten beiden Commits rückgängig machen wollt, setzt Ihr diesen Zeiger um zwei Commits zurück:
git reset HEAD~~
Die beiden Tilden stehen dabei für die Anzahl der zurückzunehmenden Commits. Führt Ihr nun wieder git log aus, seht Ihr, dass die letzten beiden Commits auch aus dem Log verschwunden sind! Davon sind dann alle Dateien betroffen, die von den Commits betroffen waren. Und keine Sorge: Auch den reset-Befehl kann man wieder rückgängig machen - es ist wie gesagt kaum möglich, mit git wirklich Daten zu verlieren ;) Aber bevor nun auch das zweite Bein im Kaninchenbau verschwindet, brechen wir hier mal ab.
5. Merging
Ein letztes wichtiges Befehlchen - super mächtig, ein Thema, das komplette Bücher füllen kann. Daher wieder nur das Nötigste: Häufig kommt es vor, dass die Arbeit (die Commits) aus einem Branch in einen anderen übernommen werden soll. Man kann einzelne Commits über Ihre IDs/Hashes von Branch A nach Branch B kopieren (git cherry-pick 123456 ...), aber die Regel ist eher: Den ganzen Ast mit einem anderen verschmelzen - auf Englisch eben das Merging.
Angenommen, Ihr entwickelt Euer Projekt auf dem Branch "master" und habt ein neues Feature oder einen neuen Teil für eine Webseite in einem Branch "spielwiese". Nun könnt Ihr jederzeit alle Commits/Änderungen der spielwiese in den master-Branch übernehmen. Nutz dazu folgenden Befehl im master-Branch:
git merge spielwiese
Danach bestehen Eure Arbeitsdateien aus allen Commits aus spielwiese plus allen Commits aus master. Dies ist eine gute Stelle, um Konflikte zu provozieren, juchee :) Was genau dabei intern vorgeht, ist nicht ganz unkompliziert - doch es gibt tolle Visualisierungs-Tools wie learngitbranching.org, die Eure Git-Befehle grafisch aufbereiten. Vielleicht an dieser Stelle noch nicht ganz verständlich, hier aber schon mal ein Bild, das zwei Merge-Vorgänge zeigt:
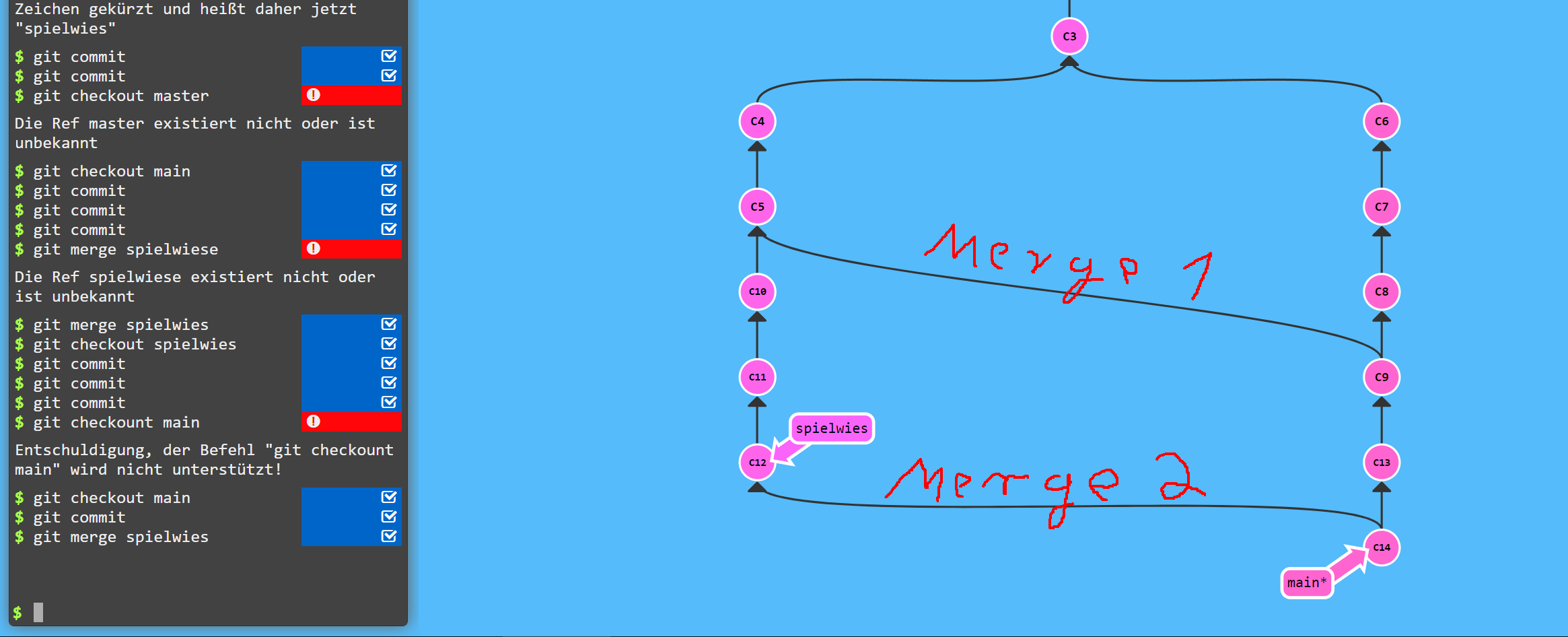
So steht Ihr nun?
Ihr könnt nun den normalen "Office-Workflow" - Speichern, Editieren, Synchronisieren - mit Git durchführen und ganz grundlegend mit Versionen und Branches umgehen. Und es gab darüber hinaus Erwähnungen von irgendwelchen HEAD-Dingern ...
Wenn diese Basisarbeit halbwegs sitzt, fängt Git schnell an auch wirklich Spaß zu machen - versprochen! Nun, die erste Hürde die kommen wird, ist der praktische Umgang mit Konflikten. Git hilft dabei enorm, kann vieles selbständig handeln und im Zweifel müsst Ihr halt die betroffene Datei öffnen und den von Git eingefügten "Konflikt-Code" manuell bearbeiten. Achtet auf die Meldungen im Prompt! Irgendwann wird auch das Zurücknehmen oder gar Kopieren von Commits in einzelne Branches Tribut fordern. Und falls es hilft: Auch gestandene Git-Profis sind dann genervt.
Um mit einem positiven Ausblick zu enden: Git bietet tolle Automatisierungs-Tools - was es mit diesen Hooks auf sich hat, habe ich bei Dev-Insider mal zusammengefasst.
Oder Ihr guckt Euch die die Visualisierung der Git-Interna an - viel Spaß!
Beitragsbild basiert auf: Peggy und Marco Lachmann-Anke from Pixabay