
Reguläre Ausdrücke und Shell Globbing habt Ihr in dieser Serie schon des Öfteren gesehen - aber meist nur so nebenbei. Zum Abschluss sollen sie nun aber auch ihren eigenen Beitrag bekommen. Einerseits sind es letztlich nur Platzfreihalter, wie das "*", nur komplexer. Ein wenig ;) Andererseits sind sie der Schlüssel für Stapelverarbeitung.
In unserer Serie zu Linux-Terminal-Basics zeigen wir Euch, wie Ihr einige der wichtigsten Aufgaben auf der Kommandozeile erledigen könnt - vom Navigieren, über Dateioperationen, bis hin zu komplexen Suchaufträgen. Als Terminal verwenden wir Bash und auch wenn Linux im Vordergrund steht, funktioniert fast alles auch unter Windows. Und nun noch die Links zur Einleitung und zur Übersicht aller Artikel.
Regex und Globbing
Zunächst mal: Was bedeuten die Begriffe überhaupt, wie unterscheiden sich die Konzepte? Details zu beiden folgen dann später.
Reguläre Ausdrücke sind komplexe Platzfreihalter - grundsätzlich standardisiert, aber mit ein paar leicht unterschiedlichen Umsetzungen (quasi Dialekten). Mit einer Regex könnt Ihr Schablonen für Wörter basteln. Das * kennt Ihr sicherlich aus einigen Suchprogrammen, ein einfacher Platzfreihalter für ein oder mehrere Zeichen (und hier keine Regex!). Wenn Ihr zum Beispiel nach MP3-Dateien sucht, dann vermutlich mit *.mp3. Oder Ihr wollt "Schmidt" und "Schmitt" in einer Textdatei finden: "Schmi*" findet alles, was mit Schmi beginnt - also auch "Schminke". Das müsste also genauer gehen. Und genau dafür gibt es Regexe.
Mit einer Regex könntet Ihr zum Beispiel ganz exakt festlegen, dass Ihr "Schmi" gefolgt von "dt" oder "tt" treffen wollt und sonst nichts. So ein Treffer nennt sich im Fachjargon Match, oft auch als eingedeutschtes Verb matchen zu sehen. Die Regex sähe hier zum Beispiel so aus: "Schmi(d|t)t" - an vorletzter Stelle dürfte also wahlweise ein t oder (|) ein d stehen.
Nun verstehen zwar allerhand Tools und vermutlich alle Programmiersprachen reguläre Ausdrücke, die Bash allerdings nicht. Stattdessen beherrscht sie Dateinamenerweiterung, was hier Shell Globbing heißt. Im Beispiel "*.mp3" von oben erweitert das Sternchen automatisch alle Dateinamen, die auf .mp3 enden. Mit einem Befehl wie
ls *.mp3
werden dann alle passenden Dateien gelistet. Natürlich geht das auch umgekehrt:
ls meine-datei.*
würde beispielsweise Dateien wie "meine-datei.mp3" und "meine-datei.doc" auflisten.
Shell Globbing ist im Grunde so eine Art Regex Light für Shell. Und wie könnte es anders sein: Sowohl Regex als auch Globbing gibt es als erweiterte (Extended) Versionen.
Ich lehne mich vermutlich nicht all zu weit aus dem Fenster wenn ich behaupte: Kaum jemand könnte Euch auswendig jedes Detail dieser Konzept herunter beten. Nicht alle Details vom erweiterten Shell Globbing sind wirklich alltäglich, Regexe gibt es in etlichen Ausprägungen und teils mit Funktionen, die Regex-Standards im Grunde überschreiten und spätestens wenn die Sprache auf Windows-spezifische Eigenheiten kommt, die eigentlich gar nicht sein sollten ..., müssen vermutlich auch gestandene Softwareentwickler mit den Schultern zucken.
Versucht also gar nicht erst alles im Detail zu verstehen und zu verinnerlichen! Wichtig ist, dass Ihr die Konzepte kennt und grundlegend anwenden und unterscheiden könnt. Wenn Ihr dann etwas Komplexeres wissen wollt ist klar, wo Ihr nachschlagen müsst und an welchen Schaltern Ihr drehen könnt.
Reguläre Ausdrücke
Zu regulären Ausdrücken haben wir bereits einen umfangreichen Beitrag - für einen praktischen Einstieg, schaut dort nach. Der Artikel fängt bei Null und landet dann irgendwann bei diesem Ausdruck:
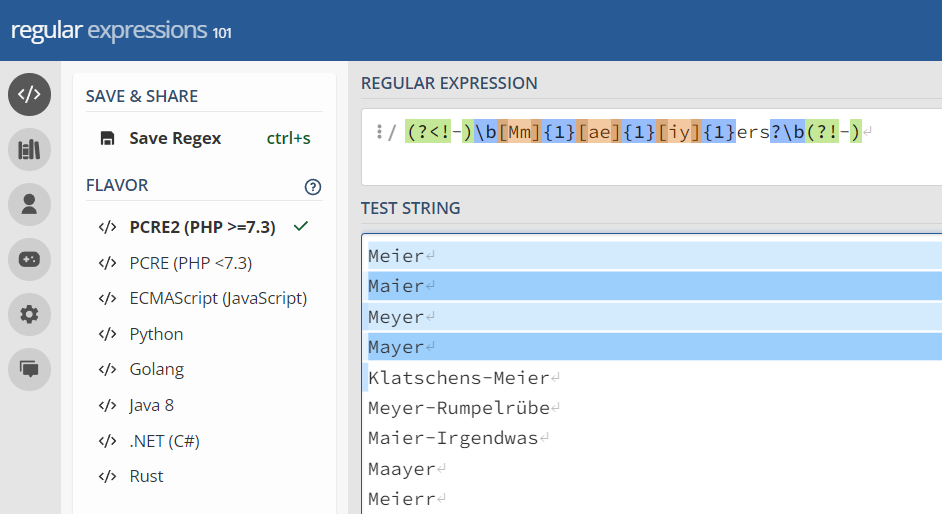
(?<!-)\b[Mm]{1}[ae]{1}[iy]{1}ers?\b(?!-)
Jaaaaaaa ... das sieht erstmal gruselig aus, einverstanden ;) Der Artikel führ Euch aber Stück für Stück dahin. Hier geht es aber eher um das Verständnis, was Regexe denn eigentlich sollen. Die Schablone matcht verschiebene Schreibweisen des Namen "Meier" in Groß- und Kleinschreibung, im Plural wie im Singular. Und etwaige Komposita wie Doppelnamen (Meyer-Schmidt) und tendenziell falsche Schreibweisen explizit nicht:
Findet:
Meier
Maier
Meyer
Mayer
mayer
mayers
und so weiter
Findet nicht:
Klatschens-Meier
Meyer-Rumpelrübe
Maier-Irgendwas
Maayer
Meierr
Eine Regex matcht Text. Ihr könntet mit dem obigen Ausdruck nun zum Beispiel einen Haufen Dokumente nach Stellen durchsuchen, die irgendwelche Meiers betreffen.
Noch zu abstrakt? Denkt mal an Eure Musik- und Videodateien. Wenn Ihr zum Beispiel eine Serie auf der Festplatte habt, wäre das hier ein typischer Dateiname: himym_S01E04.mkv für die Folge 4 der Staffel 1 der Serie "How I met your mother". In Eurem Media-Center seht Ihr freilich keine Dateinamen, sondern Episodennummer und Titel - und Zusammenfassung, Vorschaubild und so weiter. Das funktioniert in der Regel über reguläre Ausdrücke. Eine Software wie Kodi kann dann ganz einfach zu einem gegebenen Dateinamen nach einer passenden Schablone suchen und sich die passenden Informationen aus einer TV-Datenbank holen.
Der Sinn von Regexen sollte damit klar sein. In der Praxis ist es aber leider nicht die eine Regex. Zunächst mal gibt es Basic Regular Expressions (BRE) und Extended Regular Expressions (ERE). Bei den meisten Tools sind die BRE der Standard und über einen Schalter wie "-E" kann man die ERE nutzen. Bei wieder anderen Tools ist es andersrum, just for fun :)
Es gibt dabei zwei große Unterschiede: Escapes und Zeichenklassen. Escape-Zeichen sind schlicht Markierungen, die der Software sagen, dass das nächste Zeichen nicht wörtlich, sondern als Befehl zu verstehen ist - oder andersrum ... Hier ein Beispiel mit dem Standard-Escape-Zeichen \ (Backslash):
echo "(hallo)" | grep "("
echo "(hallo)" | grep -E "\("
Die erste Version findet (hallo), weil ganz einfach nach einer Klammer-Auf gesucht wird - völlig intuitiv. Die zweite Variante nutzt über den Schalter -E eine erweiterte Regex. So eine ERE interpretiert Klammern standardmäßig nicht als normale Zeichen, sondern als Klammern im semantischen Sinne (also wie zum Beispiel bei einer Matheaufgabe oder der Klammer, in der Ihr Euch just in diesem Moment befindet). Über das Escape-Zeichen wird dies außer Kraft gesetzt und die Klammer-Auf ist wieder nur noch ein simples Zeichen.
Umgekehrt:
echo "(hallo)" | grep "\("
echo "(hallo)" | grep -E "("
Hier ist das Escape-Zeichen nun in der BRE. Beide Varianten würde eine Fehlermeldung ausgeben: Sie sehen hier eben nicht mehr das Zeichen Klammer-Auf, sondern den Anfang einer Klammer - also vermissen sie Klammer-Zu!
Der zweite Unterschied sind die Zeichenklassen. Eine Zeichenklasse meint zum Beispiel "Große Buchstaben", "Kleine Buchstaben" oder "Große und kleine Buchstaben und numerische Zeichen" oder individuell etwa "3 bis 8". Und die sehen bisweilen leicht anders aus:
BRE:
[A-Z]
[a-z]
[A-Za-z0-9]
[3-8]
ERE:
[:upper:]
[:lower:]
[[:upper:][:lower:][:digit:]]
[3-8]
Bei BREs sind es Aufzählungen, bei ERE läuft es über Namen. Nützlich ist das bei weniger selbstverständlichen, aber durchaus üblichen Zeichenklassen, etwa den Whitespaces:
BRE:
[ \t\n\r\f\v]
ERE:
[:space:]
In diesem Fall ist die ERE-Notation wohl eindeutig einfacher zu merken. Nochmal: Wichtig ist erst mal vor allem, dass Ihr diesen Unterschied kennt, damit Ihr im Zweifelsfall nachschlagen könnt.
Und nein, das war es noch nicht ... Wie angesprochen, gibt es quasi Dialekte, die dann teils noch etwas mehr können - meist ist das eine Regex nach PERL-Standards, bei grep sieht das etwa so aus:
grep -P '(?<!-)\b([Mm][ae][iy]ers?)\b(?!-)'
Das ist wieder die Meier-Schablone - und die beinhaltet Dinge, die über die normalen Regex-Fähigkeiten hinaus gehen, nämlich Lookarounds. Was es damit auf sich hat, findet Ihr wieder im schon erwähnten Regex-Artikel.
Zum Merken: Es gibt Basic Regular Expressions mit Zeichenklassen als Aufzählungen und vielen vielen Escape-Zeichen. Es gibt Extended Regular Expressions (-E) mit benamten Zeichenklassen und deutlich weniger Escape-Zeichen. Und es gibt Dialekte wie Perl-Regexe, die über das normale Regex-Konzept hinaus gehen.
Shell Globbing
Falls Ihr jetzt noch aufnahmefähig seid, gibt es auch endlich etwas Praxis. Shell Globbing matcht Dateinamen, statt Text wie Regexe. Und ist deutlich simpler gestrickt.
Folgende Elemente stehen standardmäßig zur Verfügung:
* - beliebig viele beliebige Zeichen
? - ein beliebiges Zeichen
[A-Z] - Zeichenklassen wie bei Regex
Zum Auflisten und Finden von Dateien genügt das in der Regel auch schon. Ihr könnt aber auch das erweitertes Globbing aktivieren:
shopt -s extglob
Anschließend stehen Euch weitere Möglichkeiten zur Verfügung. Vor allem wird dieses mal nicht nur nach einem Muster gesucht, sondern nach einem aus einer Liste von Mustern:
?(pattern-list) - matcht 0 oder 1 Vorkommen eines der Patterns
*(pattern-list) - matcht 0 oder mehr Vorkommen
+(pattern-list) - matcht 1 oder mehr Vorkommen
@(pattern-list) - matcht Matcht 1 Vorkommen
!(pattern-list) - matcht alles außer den Patterns
Wenn Ihr also zum Beispiel alle Dateien finden wollt - warum auch immer ... -, die mit foobar oder barfoo beginnen, dann beliebige Zeichen enthalten und nicht auf .mp3 oder .mkv enden:
ls @(foobar|barfoo)*.!(mp3|mkv)
Im Alltag ist vermutlich eine ganz simple ODER-Verknüpfung das, was wirklich nützlich ist:
ls *(Meier|Maier|Mayer).txt
Shell Globbing sieht also ein wenig aus wie Regexe und verhält sich auch ähnlich - aber eben nur ähnlich. Der große Vorteil: Es steht Bash-weit zur Verfügung, die Regex-Unterstützung liegt an den einzelnen Programmen.
Grrrr... einer noch
Okay, für die Hartgesottenen hier noch eine letzte Baustelle, eine der nervigen Art. Nehmt mal folgenden Befehl:
ls *[040-050]*.mp3
Der Befehl soll alle MP3-Dateien listen, die irgendwas zwischen 040 und 050 enthalten. Unter Ubuntu funktioniert das hier auch einwandfrei, meine Windows-Bash ignoriert das hingegen und gibt alle MP3-Dateien aus. Was dafür funknioniert:
ls *{040..050}*.mp3
Die geschweiften Klammern sind keine Dateinamenerweiterung, sondern Klammererweiterung. Der Unterschied: Die gematchten Dateien müssen nicht existieren, man kann also mal eben 100 Verzeichnisse anlegen:
mkdir {001..100}
Und damit es nicht langweilig wird, heißt es eben nicht "1-10", sondern "1..10".
Warum aber nun die Zeichenklasse unter Windows per Klammererweiterung funktioniert, per Dateinamenerweiterung aber nicht? Wer weiß ... Tendenziell handelt es sich hier zwar um einen Fehler, aber um einen typischen Fehler: Viele native Windows-Versionen von Tools, die eigentlich nur unter Linux-Distributionen üblich sind, verhalten sich hier und da schon mal minimal anders. Über das Warum muss ich spekulieren: Die Linux-Version von Tools wie sed ist uralt und wird millionenfach genutzt - und gut gepflegt. Derer native Windows-Portierungen hingegen sind nicht selten Nebenprojekte von Einzelpersonen und werden auch nicht von derart vielen Menschen eingesetzt. Von daher schleichen sich dort natürlich eher mal Fehlerchen ein.
Der mutmaßliche Windows-Bash-Zeichenklassen-Globbing-Bug zeigt übrigens auf ein gutes Beispiel, wie nützlich Shell Globbing für ganz normale Menschen ist, die gar kein Intresse an Scripting oder überhaupt Computern haben. Es geht nämlich um Hörbücher! Diese liegen häufig in Form etlicher kleiner, durchnummerierter Dateien vor. Für den Einsatz auf mobilen Playern brauche ich sie aber als einige wenige große Dateien. Also fasse ich immer rund 30 Dateien zusammen:
mp3wrap.exe mein-audiobuch_21_bis_50.mp3 *0{21..50}*.mp3
Darüber verschmilzt mp3wrap die MP3-Dateien mit den Nummern 021 bis 050. Und da mp3wrap selbst keine Regex unterstützt, wäre es ohne die Bash-interne Funktion so einfach gar nicht möglich. Trotzdem baue ich ständig eckige Klammern an der Stelle ein ... sollten halt auch funktionieren :(
Wenn Ihr im Terminal Hilfe zur Syntax benötigt, fragt doch mal unsere hauseigene Linux-Hilfe cli.help:
curl cli.help/regex
Und regelrecht unverzichtbar: Der Regex-Spielplatz regex101.com - zum Ausprobieren und Erklärenlassen:
Und wer nach all dem Techie-Brainfuck endlich mal wieder was Bodenständiges ohne Gefrickel sucht ... wie wäre es mit 'ner Scheibe Brot?


Schön geschrieben. So macht es Spaß zu lesen und zu lernen.
cli.help funktioniert bei mir nicht über die Kommandozeile; weder Linux noch Windows Powershell. Ich erhalte die Fehlermeldung, dass der Hostname nicht aufgelöst werden kann. Im pihole ist es freigegeben, da steht SERVFAIL. Mit dem Browser funktioniert es.
Wo ist mein Fehler? (Gern auch per Chat)
Danke!
Dass cli.help nicht läuft, kann eigentlich nur irgendwo an der Pi-Hole-Config oder irgendwelchen komischen Weiterleitungen im Netzwerk liegen (auf cli.help lieg en nur reine Textdateien, da gibt es nicht mal HTTPS). Für die SERVFAIL-Meldung scheint es bei Pi-hole allerlei Gründe geben zu können – bei denen ich aber nicht weiterhelfen kann, weil ich das nicht nutze. Vielleicht liefert dieser Threat im Pi-hole-Forum ein paar Hinweise.
Danke. Ich schau mal,wo es hängt.