Das Jahr 2302, ein totalitäres Regime hat die Erde fest im Griff. Die Basis des Erfolgs: Alle Menschen sind registriert und lassen sich jederzeit auffinden. Nun, fast alle ... Die Uneindeutigen fanden immer Wege, dem System zu entkommen. Siegelbert Funkenschwurgel III. - eindeutig! Aber Peter Schmid? Oder Peter Schmidt? Oder Peter Schmitt? Schmit? Aarrgh ... - uneindeutig. Aber darum hat man sich gekümmern, in jahrelanger Kleinarbeit. Sie wurden umbenannt, in Gurgelfark. Doch nun lauern noch die Meiers, die Maiers, die Meyers, die ganze Meute halt. Die Ressourcen sind knapp, die Zeit drängt - wie findet man all die "Maeiyers" schnell? Auftritt Captain RegEx!
Regex = mächtiges, mächtiges "*"
Ihr sitzt nun also im 453. Stock eines mittelgroßen Bürogebäudes, irgendwo unter dem mittleren Management, und arbeitet als Datenanalyst, aka Uneindeutigen-Jäger. Ihr habt einen 500 Petabyte großen Datenhaufen mit allen Daten über Menschen und Namen und wollt nicht weniger als das System retten - vor den Uneindeutigen, die ihre ambivalenten Namensschreibweisen für das Abtauchen in den Untergrund nutzen und am schönen Konformismus rütteln. Was also ist zu tun?
Als gewiefter Analyst hat man schnell Sternchen in den Augen - warum nicht einfach nach
M*er
suchen? Na, so gewieft wohl doch nicht - das fänd nämlich zum Beispiel nicht Familie Mayr, dafür aber alle Maler, Müller und Mütter ...
Und nun kommt die Stunde von Captain RegEx: "Depp, machsu Regex und gut is'!" Und da hat er wohl recht: Ein regulärer Ausdruck, oder eben Regular Expression (Regex), ist im Grunde nichts weiter als ein komplexes komplexes "*". Das "*" kennt Ihr als Platzfreihalter etwa von Suchen bei Google oder im Dateibrowser. Es steht einfach für irgendwas beliebig oft. All die Maeiyer-Varianten fangen zwar mit M an und hören mit r auf, aber dazwischen darf nicht Beliebiges stehen.
Captain RegEx' Superkräfte
Des Captains Lieblingswaffe kann hier nun intervenieren und präzise festlegen, was zwischen M und r stehen oder nicht stehen darf. Und auch was davor und dahinter stehen darf oder nicht! Denn nach kaiserlichem Erlass von 2299, ein Jahr nach dem Ende der Karenzzeit für freiwillige Umbenennung, sind Doppelbenamte (aka Hypereindeutige) von der Verf ..., äh, Auffindung ausgenommen. Familien wie Klatschens-Meier und Meyer-Rumpelrübe stehen explizit über den Dingen.
Frage 1: Was genau soll denn beschrieben werden? Eine Datenanalyse hat abseits aller theoretischen weiteren Varianten die folgenden als einzig relevante eingeordnet:
Meier
Maier
Meyer
Mayer
Doch ach, was, wenn irgendwo versehentlich meier mit kleinem M steht? Oder irgend wo von Herrn Meiers Idee die Rede ist? Also müssen auch Schreibweisen wie
meier
Mayers
gefunden werden. Was, wenn jemand wirklich Maayer oder Meierr heißt? Und die Hypereindeutigen müssen auch raus, Folgendes darf also nicht gefunden werden:
Klatschens-Meier
Meyer-Rumpelrübe
Maier-Irgendwas
Maayer
Meierr
Ihr seht schon, mit einem simplen Sternchen ist es da nicht getan.
Frage 2: Wie funktioniert denn nun eine Regex? Der nächste Satz wird die Phrase im Grunde ganz einfach enthalten - um das im Grunde zu präzisieren, hier mal die finale Lösung als Spoiler:
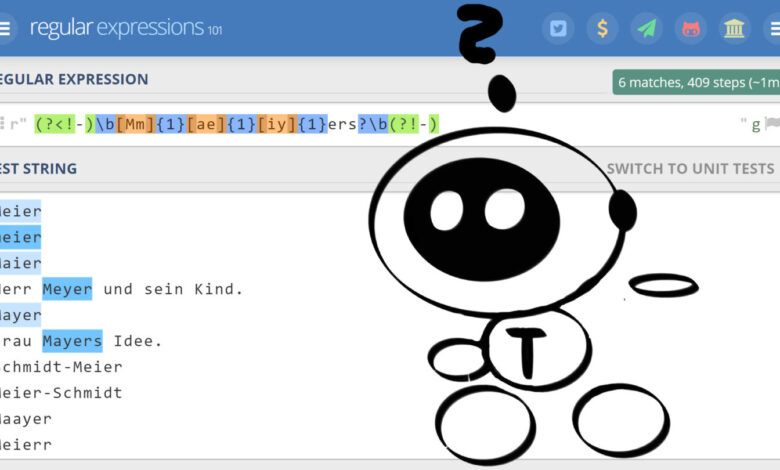
(?<!-)\b[Mm]{1}[ae]{1}[iy]{1}ers?\b(?!-)
Jetzt mal ohne Witz, das ist doch intuitiv für jedes Kleinkind verständlich, ist es nicht?! Zum Testen von solchen Ausdrücken könnt Ihr die extrem gute Seite Regex101.com nutzen.

Regex-Basics
Die Geschichte mit den regulären Ausdrücken ist im Grunde ganz einfach: Ihr beschreibt, wie eine Textstelle aussehen soll, auf welche Zeichenfolge die Regex "matcht", wie man so schön sagt. Ihr könnt Zeichen direkt festlegen, Zeichen zur Auswahl angeben ([]), die Anzahl der zuvor erlabten Zeichen festlegen ({}) und Begrenzungen, etwa auf ein einzelnes Wort (\b), verwenden. Kompliziert sieht es nur durch die Syntax aus.
Die wichtigste Syntax:
[aAbZ] --> Auswahl erlaubter Zeichen; hier a, A, b und Z.
[[:digit:]] --> Auswahl erlaubter Zeichen; hier Ziffern.
{1,3} --> Erlaubte Anzahl der Zeichen; hier 1 bis 3.
* --> Voriges Zeichen beliebig häufig.
? --> Voriges Zeichen 0 oder 1 mal.
. --> Beliebiges Zeichen.
foobar --> Einfach die angegebene Zeichenfolge foobar.
\ --> Escape-Zeichen: Das folgende Zeichen wird als "Befehl" verstanden, wenn es eigentlich ein Zeichen ist - und umgekehrt.
\. --> Der Platzfreihalter . wird escaped und wörtlich als Punkt verstanden.
\b --> Das Zeichen b wird escaped und als "Befehl" Wortbegrenzung verstanden.
(foo.*bar) --> Alles in runden Klammern ist eine Match-Gruppe, die in einer Variablen gespeichert wird.
^ --> Anfang einer Zeile.
$ --> Ende einer Zeile.
Mal ein simples Beispiel: Gefunden werden sollen (Zeilen mit!) Beet und Bett:
Be[et]{1}t
Die Zeichenfolge muss mit Be anfangen, mit genau einem e oder einem t fortfahren und schließlich auf t enden. Gefunden werden Beet und Bett, also zum Beispiel in folgenden Zeichenfolgen:
Bett
Beet
foobarBeet
fooBettBAR
Daher gibt es die Wortbegrenzung (\b): An der Stelle muss also ein Zeichen stehen, das ein Wort vom nächsten Wort abtrennt, zum Beispiel Leerzeichen oder (später noch wichtig) Bindestriche:
\bBe[et]{1}t\b
Beet und Bett in folgenden Varianten würden damit gefunden, Dinge wie fooBettBAR aber nicht:
Bett
Beet
Bett-Geställ
Beet und Baum
Das {1} könnt Ihr übrigens weglassen, weil 1 sowieso der Standard ist, wenn Ihr nichts angebt.
Nun noch ein letztes Beispiel, bevor Ihr endlich Maeiyers jagen dürft, um die Match-Gruppen zu verstehen: Stellt Euch eine simple Liste mit dem Muster NACHNAME VORNAME vor:
Pan Peter
Duck Donald
Simpson Homer
Wenn Ihr lieber VORNAME NACHNAME haben wollt, könnt Ihr eine Regex nutzen, die beide Wörter je in eine eigene Match-Gruppe packt:
(.*) (.*)
Die Regex beschreibt also: Anfang Match-Gruppe 1, beliebiges Zeichen in beliebiger Anzahl, Ende Match-Gruppe 1, Leerzeichen, Anfang Match-Gruppe 2, beliebiges Zeichen in beliebiger Anzahl, Ende Match-Gruppe 2.
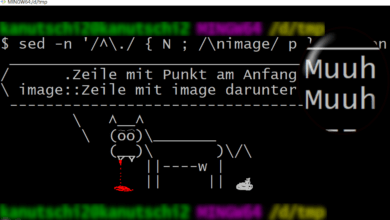
In der Praxis nutzen etliche Tools reguläre Ausdrücke, für diese Aufgabe eignet sich sed (grundsätzlich: "sed s/SUCHWORT/ERSATZ/") hervorragend:
sed -r 's/(.*) (.*)/\2 \1/g'
Das -r erlaubt erweiterte Regexe, das s startet die Suche, zwischen den nächsten beiden // steht die obige Regex als Suchbegriff und anschließend wird der komplette Match mit \2 \1 überschrieben: Match-Gruppe 2 (Nachname), Leerzeichen, Match-Gruppe 1 (Vorname). Das abschließende g steht für global, ansonsten würde sed nur den ersten Match pro Zeile verarbeiten.
Nieder mit den Maeiyers
Also wieder zurück zur oben gespoilerten Regex für die Meier-Schreibweisen, aber ohne die überflüssigen Quantifizierer ({1}):
(?<!-)\b[Mm][ae][iy]ers?\b(?!-)
Aber ein Stück zurück, da ist ja noch Voodoo drin:
\b[Mm][ae][iy]ers?\b
Hier ist jetzt nur Bekanntes vorhanden, gesucht wird: Wortbegrenzung, ein M oder ein m, ein a oder e, ein i oder y, dann er, ein oder kein s, Wortbegrenzung. Gefunden werden nun alle gewünschten Schreibweisen:
Meier
Maier
Meyer
Mayer
Upps, oben haben wir noch Familie Mayr erwähnt ... Mist. Wenn Ihr so bayrisch anmutende Schreibweisen ohne e hinten auch zulassen wollt, setzt einfach auch dahinter ein ? - wie oben erwähnt, steht es für eins oder keins:
\b[Mm][ae][iy]e?rs?\b
Das aber nur zur Verdeutlichung. Noch werden aber auch die Hypereindeutigen gefunden, denn auch eine Zeile wie
Herr Klatschens-Meier hat Husten.
matcht. Warum? Weil der böse Bindestrich leider zu den Wortbegrenzern gehört.
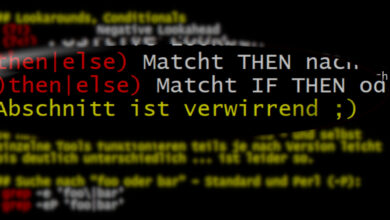
Und jetzt - ja, erst jetzt! - wird es etwas frickelig: Regexe werden eigentlich nur von vorne nach hinten durchgearbeitet. Nun soll aber eine Definition her wie: Match, wenn eine Meier-Schreibweise passt, aber nicht, wenn davor ein Bindestrich steht. Es muss also quasi nach hinten geguckt und sichergestellt werden, das der Bindestrich negativ (nicht vorhanden) ist. Und darum nennt sich die Konstruktion auch Negative Lookbehind. Bei Meyer-Rumpelrübe braucht es hingegen einen Negative Lookahead, um sicherzustellen, dass vorne, also hinter dem Match auch kein Bindestrich ist:
(?<!-)\b[Mm][ae][iy]ers?\b(?!-)
(?<!-) ist der Negative Lookbehind, (?!-) der Negative Lookahead, in beiden ist der Bindestrich als Ausschlusszeichen einfach hinten angehängt.
Und damit könnt Ihr nun die abgetauchten Uneindeutigen mit den ambivalenten Schreibweisen nun in Eurem riesigen Datenberg suchen und zum Beispiel zu Meier-Doofmann, Meyer-Doofmann und so weiter umbenennen. In einem Haufen Textdateien genügt zum Beispiel ein
perl -pe 's/(?<!-)\b([Mm][ae][iy]ers?)\b(?!-)/\1-Doofmann/g'
Die Meier-Schreibweisen sind hier in einer Match-Gruppe, die dann beim Ersetzen durch -Doofmann ergänzt wird.
Die eigentliche Frage ist: Warum perl und nicht sed? Tja, die ganzen unterschiedlichen Maeiyers habt Ihr zwar gefunden, aber Captain RegEx ist ein komplizierter Typ ... - und ein bisweilen gieriger Tyrann!
Kompliziert, aber nützlich
Reguläre Ausdrücke sind in der Praxis nicht ganz so reguliert, wie man das vielleicht meinen möchte. Es gibt verschiedene Varianten und nicht jedes Tool kann mit jeder Variante umgehen. sed zum Beispiel versteht Lookarounds nicht, perl schon. Beim Standard-Such-Werkzeug unter Linux, find, lässt sich zum Beispiel explizit aus etlichen Varianten wählen. Das macht das ohnehin schon mächtige Tool noch mächtiger, und komplexer ...
Es gibt viele Regex-Kleinigkeiten, mit denen Ihr Euch über Jahre beschäftigen könnt. Das beginnt mit Kleinigkeiten wie Ziffern zu matchen, mal heißt es [[:digit:]] (POSIX-Style), häufiger [0-9] und auch \d ist anzutreffen. Und nicht immer funktionieren sie hundertprozentig identisch. Schön ist hingegen, dass es bei Regexen meist mehrere Lösungen gibt. Wenn Ihr die Maeiyers ohne Lookarounds auffinden wollt, könntet Ihr den Namen zum Beispiel manuell durch erlaubte Zeichen davor und dahinter erweitern, statt auf die Vereinfachung mit den Wortbegrenzern zu nutzen - wenn Ihr den Bindestrich gar nicht erst einschließt, müsst Ihr ihn auch nicht mit Lookarounds-Krücken wieder ausschließen.
Ihr seid keine Datenanalysten im 24.Jahrhundert? Regexe sind dennoch wahnwitzig nützlich, zum Beispiel, wenn es um das Umbenennen von Dateien geht. Ein Leser fragte neulich, wie er PDF-Dateien, deren Dateinamen Datum und Uhrzeit enthalten und daher immer unterschiedlich sind, trotzdem automatisiert auf seinen Telegram-Account bekommt - die Lösung: Regex. Oder wie wäre es mit einer eigenen Markup-Sprache? Bei redundatenen Verwaltungsaufgaben sind Regexe ein wesentlicher Baustein, um viele Stunden Zeit zu sparen.
Generell aber sind Regex schlicht immer dann sehr nützlich, wenn Ihr in großen Datenbeständen etwas sucht - seien es alle Email-Adressen in 3.000 PDF-Dokumenten oder alle Verweise auf Buch XY in einer digitalen Bibliothek mit vielen Millionen Schriften. Und zweitens, wenn Ihr etwas automatisieren wollt, zum Beispiel Backups, bei denen bestimmte Dateien ein- und/oder ausgeschlossen werden.
Und wenn Ihr immer noch nicht glaubt, dass Regex die perfekte Mischung aus Spaß und Superkraft ist: Regexe gibt's sogar als Spiel für Android ;)
Falls Ihr bis hierhin gelesen habt, interessiert Euch vielleicht auch unsere hauseigene Linux-Hilfe für die Kommandozeile: cli.help