Zugegeben, der Fall ist recht speziell, aber die Vorgehensweise funktioniert auch bei Listen mit Fußballergebnissen oder Apple-Kundenprofilen. Die Aufgabe: Es gibt eine Liste A mit Tausenden Domains und eine Liste B mit noch mehr Domains, hier aber samt Herkunftsland. Das Ergebnis soll eine Liste mit allen Domains samt Land sein, die in beiden Listen vorkommen. Und die sollen danach noch ...
... darauf geprüft werden, ob sie bei einem Domain-Hoster geparkt werden. Wie gesagt, speziell.
Das Beispiel wird mit dem original Listenlayout durchexerziert, daher sind hier und da ein paar Zwischenschritte nötig, etwa Kommata eliminieren - und auch Ihr werdet in der Praxis selten "perfekte" Listen zum Verarbeiten bekommen, wetten? Auch ist das nicht immer alles super-elegant gelöst. Einerseits, weil hier kein Skript für die Ewigkeit entstehen sollte, sondern nur einmalig ein Quick'n'Dirty-Ergebnis. Zum anderen ist es teils einfacher nachzuvollziehen, beispielsweise wenn ein Zwischenschritt nicht in einer Variablen landet, sondern in einer Hilfsdatei.
Das ganze findet in einem Linux-Terminal, hier der Bash, und mit simplen Test- oder CSV-Textdateien statt. Auf geht's, zum fröhlichen Listen vergleichen - Yeiii!
Schnittmenge von Liste A und Liste B
Alle relevanten URLs aus Liste A (Text-Liste) sind auch in Liste B (CSV) - erstmal muss also eine Liste mit der Schnittmenge her. Hier erstmal die Listenlayouts:
Liste A:
gizlog.de
example.com
example.de
example.org
tutonaut.de
Liste B:
foo.com,USA
example.com,USA
example.de,BRD
example.org,NZ
foo.org,AT
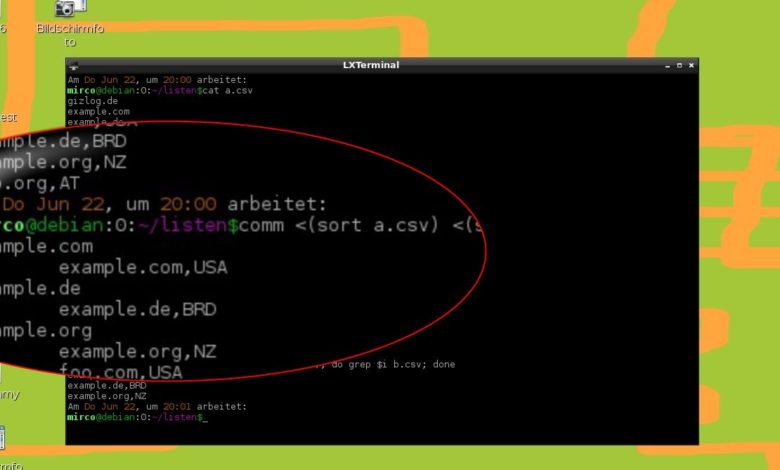
Das Tool der Wahl ist comm. comm vergleicht zwei Listen Zeile für Zeile und gibt dreispaltig aus: Einträge, die nur in der ersten Listen sind, nur in der Zweiten und letztlich in beiden vorkommen. Die Listen müssen sortiert werden, was sort erledigt. Aber: Eine Zeile in unserer Beispielliste B ist ja immer länger als das Gegenstück in Liste A - es sollen also nur dir URLs bis zum Komma verglichen werden. Und so sieht das dann aus.
comm -1 -2 < (sort A.csv) <(cat B.csv | awk -F',' '{print $1}'|sort) > schnittmenge.csv
Die Parameter: comm -1 -2 Gibt von den drei Spalten nur die letzte aus, mit den Einträgen, die in beiden Listen vorkommen. Die spitze Klammer Liest das Ergebnis der Aktion in der folgenden Klammer ein. (Wordpress will die Klammer nicht im normalen Text anzeigen ...) sort Sortiert die Liste alphabetisch. awk Untersucht einen übergebenen String/Text, hier Liste B. -F',' Definiert das Komma als Separator zwischen Feldern, hier URL und Land. '{print $1}' Gibt das erste Feld aus, hier also die URL.
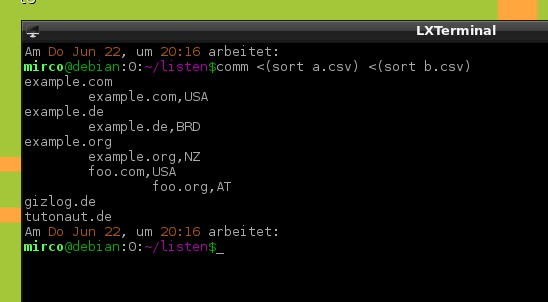
Die Liste mit allen URLs der Schnittmenge landen in der Hilfsdatei schnittmenge.csv. Natürlich könnt Ihr auch die exklusiven Mengen und die Vereinigungsmenge auslesen, indem Ihr die entsprechenden Spalten mit -1, -2, -3 außen vor lasst.
Schnittmengen-Einträge aus Liste B extrahieren
Die Schnittmenge liegt jetzt als reine URL-Liste vor, es fehlen die Länder. Jetzt sind die Tools der Wahl: Eine for-Schleife und grep. Die Schleife liest jeden Eintrag aus der Schnittmengenliste und übergibt ihn grep - und grep sucht dann danach in der Liste B und gibt bei Treffern die jeweilige Zeile aus. Also die URL samt Land.
for i in $(cat schnittmenge.csv); do grep $i B.csv; done
for i in $ weist der Variablen i den jeweiligen Wert der Klammer-Anweisung zu. "Jeweilig" heißt hier, dass jede ausgegebene Zeile (=URL) nach einander "i ist". do ist dann einfach die Anweisung für jede i-Version; hier sucht eben grep den jeweiligen Wert der Variablen in Liste B. Done beendet die Schleife. Das Ergebnis ist also die finale Liste:
Liste C
example.com,USA
example.de,BRD
example.org,NZ
Moooooment ...
Ist Euch was aufgefallen? In Schritt 1 ermittelt comm alle Einträge, die in A und B vorkommen. Und Schritt 2? Ermittelt alle A-Einträge in B - also exakt das gleiche. In der schnittmenge.csv sind natürlich nur Einträge, die passen, aber selbst wenn weitere drin wären - egal, grep würde ja nur Zeilen mit Treffern ausgeben. Also:
for i in $(cat A.csv); do grep $i B.csv; done
Und schon sieht es doch deutlich freundlicher aus, gell?! Wenn die Routine fehlt ..., geht es beim Skripten eben auch mal über Umwege. Aber das ist auch das Schöne an der Arbeit im Terminal: Es gibt fast immer mehrere mögliche Lösungen. Zumal: Die schnittmenge.csv ist natürlich dennoch nützlich, weil eine reine URL-Liste ohne Land-Ballast leichter weiterverarbeitet werden kann (erspart nochmaligen awk-foo).
Naja, in diesem Fall passt die Lösung perfekt - die erste passt aber universell, da Ihr aus beiden gegebenen Listen beliebige Bestandteile ausblenden und das Übrige miteinander vergleichen könnt. In der zweiten Lösung ließe sich das natürlich wieder im grep-Kommando unterbringen ...
URLs crawlen
Bei der Auswertung von Liste A viel irgendwann auf, dass einige Domains bei einem Hoster geparkt waren, vermutlich, weil ihre Besitzer keine Weiterleitungen eingerichtet haben. Aber Hunderte URLs manuell prüfen? Nö. Die Geparkt-Seite des Hosters zeigt die eingegebene URL immer in der Form < <example.com>> - was liegt also näher, als die for-Schleife nochmal rauszuholen und alle URLs zu crawlen?
Am Ende sah das ganze dann so aus:
for i in $(cat A.csv); do curl $i | html2text -utf8 | egrep "(\».+\)"|tr -d '»' | tr -d '«' | tee -a tee-result; done
Die for-Schleife rotiert wieder durch jede Zeile der Liste A, wie gehabt. Im do-Part besorgt nun curl die jeweiligen Websites, sprich die Geparkt-Seiten. Über html2text lässt sich dann sauber formatierter Text bauen.
Auch egrep ist bekannt - das ist einfach ein Kürzel für "grep -e", eine Option, die erweiterte Suchparameter, so genannte Reguläre Ausdrücke ermöglicht. In diesem Fall sucht egrep nach » (der \ sagt an, dass das folgende Zeichen kein Steuerzeichen ist, sondern das zu suchende Zeichen), dann nach beliebigen Zeichen (.) in beliebiger Menge (+) und dann nach «.
Weiter geht es mit zwei tr-Anweisungen: tr löscht über den Parameter -d die spitzen Doppelklammern - schließlich soll die finale Liste nur URLs enthalten, keine lustigen Pfeile. tee ist dann endgültig optionale Spielerei: tee hängt die Ausgabe (-a für append) an die Datei tee-result an und gibt sie gleichzeitig im Terminal aus. Das ist immer praktisch, wenn Ihr Skriptausgaben in eine Datein schreiben und gleichzeitig live sehen wollt.
Und mit dieser Liste könnte man dann mal zu den Web-Leuten gehen und sie bitten, Weiterleitungen einzurichten oder die Domains zu kündigen. Oder zumindest Werbung zu schalten ...
Und, überzeugt? Der Terminal ist super für Listen, oder!? Mehr? Hier!