Markdown hat das Schreiben von Blog-Artikeln, HTML-Dokumenten und allerlei sonstigen Textdateien enorm vereinfacht. Aber Markdown ist nicht immer und überall verfügbar und passt vielleicht nicht genau für Eure Zwecke. Mit einem eigenen Markup könnt Ihr beliebige Textauszeichnungen setzen, oder auch Textbausteine verwenden. Und das mit einer Syntax, die Ihr Euch selbst ausgedacht habt - und die dadurch extrem einfach zu merken ist.
Auf zu ein wenig guter alter Spielerei ;)
Vorsicht: Entschuldigt bitte, aber an einigen Stellen im unten gezeigten Code haben sich Fehler eingeschlichen, die das dämliche Wordpress eingebaut hat - Wordpress interpretiert HTML-Code normalerweise, daher fällst es ihm offenbar schwer, ihn stattdessen darzustellen. Es lässt sich gerade aber nicht abstellen ... Den korrekten Code findet Ihr in dieser Textdatei.
Tool der Wahl: sed
sed ist eine universelle Lösung für derlei Aufgaben: Die Textverarbeitung für den Terminal eignet sich wunderbar, um größere Mengen an Textdateien zu modifizieren, ist überall verfügbar und sehr gut dokumentiert. Und auch wenn es auf den ersten Blick nicht so aussehen mag, ist es auch eine der einfacheren Varianten. Im Grunde ist sowas wie Markdown nichts weiter als umfangreiches Suchen & Ersetzen.
Dafür kommen reguläre Ausdrücke ins Spiel - supermächtiges Zeugs! Wer sie grundlegend kennt, wird in diesem Artikel lediglich einen einfachen Denkanstoß finden. Wer sie nicht kennt einen etwas brutalen Crash-Kurs ...
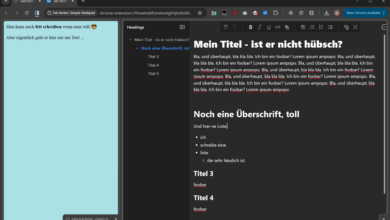
Und hier eine kleine Vorschau:
Markup bauen
Als Beispiel könnt Ihr ein vereinfachtes/individuelles Markup für HTML basteln - das ist so schön eingängig und nützlich, wenn man gerne offline bloggt. Das Prinzip ist wie bei Markdown: Ihr denkt Euch eine Auszeichnung für irgendein HTML-Element aus, beispielsweise Überschriften, Fettungen, Links:
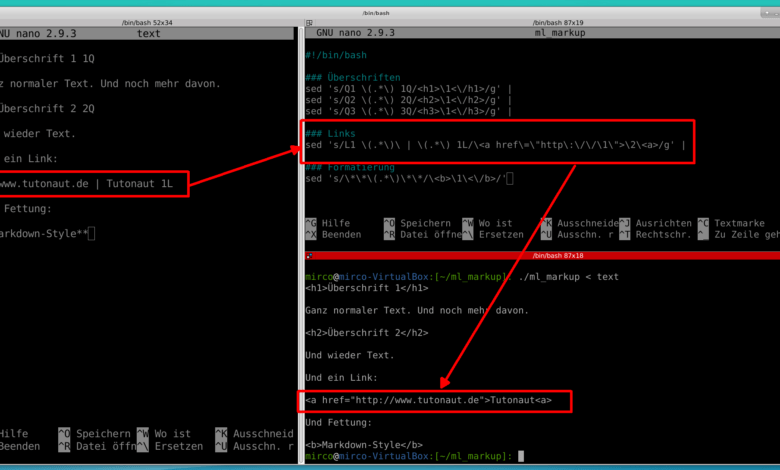
Q1Überschrift 11Q
**Etwas Fettes**
L1 www.tutonaut.de | Tutonaut 1L
Und dann braucht Ihr sed-Befehle, die aus der Überschrift zwischen Q1 1Q eine HTML-Überschrift und aus dem Text zwischen den Sternchen fetten Text machen - letzteres ist natürlich auch ein Markdown-Standard. Und der Link verlangt noch nach etwas mehr Aufmerksamkeit.
Markup-Übersetzer bauen
Das Tool der Wahl ist wie gesagt sed, aber das eigentliche Werkzeug sind reguläre Ausdrücke. Und ja, die sehen gruselig aus, aber nur auf den ersten Blick (nun, vielleicht auch auf den zweiten ;) ). So eine Regular Expression, kurz RegEx, beschreibt einfach nur eine Zeichenkette - und in diesem Fall ist sie ziemlich einfach, erstmal in Menschensprache. Gesucht wird:
Text zwischen Q1 und 1Q
Text zwischen doppelten Sternchen
Text zwischen L1 und 1L - plus ... später mehr
Ein regulärer Ausdruck (für sed) für die Überschrift:
Q1\(.*\)1Q
Damit wird eine Zeichenkette gefunden, die mit Q1 anfängt und mit 1Q aufhört - ein Match. Dazwischen darf alles stehen: . heißt beliebiges Zeichen, Sternchen heißt beliebige Menge. Das Ganze steht in runden Klammern, die jeweils mit den Backslashes escaped werden - das heißt, sed erkennt sie als Befehl, nicht wörtlich das Zeichen "Klammer auf/zu". Der Grund für die Klammern: Der Inhalt, eine Match-Gruppe, wird automatisch in einer Variablen gespeichert, die später wieder ausgegeben werden kann. Schließlich sollen ja nur die Qs verschwinden, nicht aber der Text der Überschrift.
Ersetzt werden soll das Ganze dann durch:
<h1>Überschrift 1</h1>
wobei Überschrift 1 eben aus der Variablen kommen wird. Bei sed sieht ein Suchen-und-Ersetzen-Befehl von der Form her immer gleich aus:
sed s/suchen/ersetzen/g
Das g sagt, dass das für den ganzen Text durchgeführt werden soll. Und jetzt wird es - für RegEx-Einsteiger - etwas, sagen wir hübscher:
sed 's/Q1\(.*\)1Q/<h1>\1< \/h1>/g'
Zwischen den ersten beiden Slashes steht der obige Ausdruck, der die markierte Überschrift findet. Zwischen den zweiten beiden Slashes steht der Ersatz: Erst wird das öffnende h1-Tag geschrieben, wobei die erste Klammer wieder per Backslash escaped werden muss. Der Inhalt der Klammer von oben wird dann über die Variable \1 ausgegeben, gefolgt von dem schließenden h1-Tag. Das zu erwartende Ergebnis:
</h1><h1>Überschrift 1</h1>
Achtung: Das SPITZE-KLAMMER-AUF/h1> am Anfang der letzen Zeile gehört nicht dazu - das macht das doofe Wordpress; hier sind zu viele HTML-Zeichen, die Wordpress unbedingt interpretieren will ...
Bei der Fettung sieht es fast genauso aus, hier mal Ausgangstext, sed-Befehl und Ausgabe:
**Etwas Fettes**
sed 's/\*\*\(.*\)\*\*/\<b>\1\< \/b>/'
</b><b>Etwas Fettes</b>
Achtung: Das SPITZE-KLAMMER-AUF/b> am Anfang der letzen Zeile gehört nicht dazu - das macht das doofe Wordpress; hier sind zu viele HTML-Zeichen, die Wordpress unbedingt interpretieren will ...
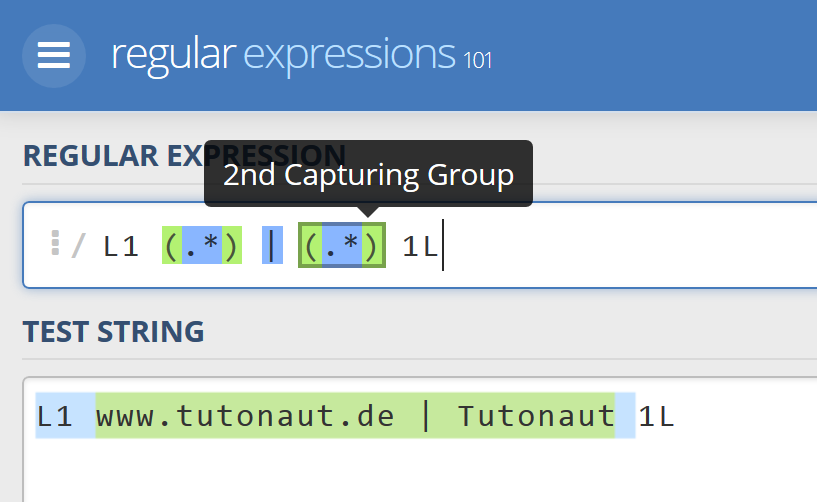
Beim Link wird es etwas komplexer, weil es zwei Klammern/Match-Groups gibt, hier wieder alle drei Schritte:
L1 www.tutonaut.de | Tutonaut 1L
sed 's/L1 \(.*\)\ | \(.*\) 1L/\<a href\=\"http\:\/\/\1\">\2\< \/a>/g'
</a><a href="https://www.tutonaut.de">Tutonaut</a>
Achtung: Das SPITZE-KLAMMER-AUF/a> am Anfang der letzen Zeile gehört nicht dazu - das macht das doofe Wordpress; hier sind zu viele HTML-Zeichen, die Wordpress unbedingt interpretieren will ...
Was hier passiert: Der reguläre Ausdruck findet das www.tutonaut.de über die erste Klammer/Match-Group und Tutonaut über die zweite Klammer/Match-Group. Angesprochen werden die Match-Gruppen über die Variablen \1 und \2. Und daraus wird dann wieder ein HTML-Tag gebaut.
So hässlich ist das Ganze durch die Escaperei, für die es irgendwie auch keine gebräuchlichen deutschen Wörter gibt. Über so ein Escape-Zeichen wird nicht nur bei RegExen, sondern zum Beispiel auch bei farbigen Terminal-Ausgaben gearbeitet.
Die korrekte Syntax für eine RegEx zu finden, ist nicht ganz einfach, wenn man nicht täglich mit sowas umgeht. Das wohl beste Hilfsmittel: Bei Regex101.com könnt Ihr Texte und reguläre Ausdrücke eingeben und anschauen, was passt und was nicht - dabei wird die RegEx in alle Bestandteile zerlegt und erklärt. Ganz trivial ist das Thema aber nicht: Es gibt immer mehrere Wege etwas zu definieren, unterschiedliche Ausprägungen bezüglich Features und Syntax und kleine Gemeinheiten.
Ein Einsatzbeispiel
Um daraus nun Nutzen zu ziehen und eine eigene Markup-Sprache zu haben, braucht es natürlich viele solcher Definitionen, zusammengefasst in einem Skript. Mal ein ganz konkretes Einsatzbeispiel: Ihr erstellt Inhalte für eine Webseite in Form von Textdateien mit Eurem Markup. Diese konvertiert Ihr dann mit Eurem Markup-Skript in die HTML-Formatierung, kopiert sie in das Web-Verzeichnis Eures lokalen Webservers und schon habt Ihr eine aktuelle Version der Webseite im fertigen Layout.
Und wer mehr will: Ihr könntet auch gleich noch den Browser aufrufen und/oder aktualisieren und das Skript alle Dateien Eures Arbeitsordners verarbeiten lassen, ein Tastenkürzel für das Skript anlegen und schon könntet Ihr mit nur einem Tastendruck Markup-Seiten in HTML-Seiten verwandeln und sofort im Browser betrachten.
Aber das soll hier kein Grundkurs in Scripting werden, daher nur die minimale Basis für Eurer Markup-Skript namens mein_markup:
#!/bin/bash
### Überschriften
sed 's/Q1\(.*\)1Q/<h1>\1< \/h1>/g' |
sed 's/Q2\(.*\)2Q/<h2>\1< \/h2>/g' |
sed 's/Q3\(.*\)3Q/<h3>\1< \/h3>/g' |
### Links
sed 's/L1 \(.*\)\ | \(.*\) 1L/\<a href\=\"http\:\/\/\1\">\2\</a>/g' |
### Formatierung
sed 's/\*\*\(.*\)\*\*/\<b>\1\< \/b>/'
Hier sind jetzt noch Zeilen für die Überschriften 2 und 3 dabei. Nach jeder Zeile wird der veränderte Text via | an den nächsten Befehl weitergeleitet. Das ist im Grunde Käse: Ihr könnt und solltet natürlich einen sed-Befehl mit vielen einzelnen Ersetzungen nutzen. Der kleine Vorteil hier: Ihr könnt immer wieder Zeilen per Copy&Paste einzeln nutzen, sofern gewünscht. Der Aufruf des Skripts:
./mein_markup < eine_textdatei.txt > eine_andere_textdatei.txt
Wie gesagt, je nachdem wie Ihr das einsetzen wollt, müsst Ihr ein wenig Skript drum herum stricken. Beispielsweise um mehrere Dateien zu verarbeiten, Dateien zu verändern statt zu kopieren oder sie in das Web-Verzeichnis zu kopieren.
Abseits von HTML
Aber nicht bloß für HTML-Dokumente ist so ein Skript praktisch. Ihr könnt es als simples Textbausteinsystem verwenden: Warum nicht ein simples #sg durch Sehr geehrte Damen und Herren, \n ersetzen? Oder Mitarbeiterkürzel durch deren komplette Namen? Vielleicht könnt Ihr Euch auch die Syntax für if-Schleifen in der Bash nicht merken - wie wäre es mit:
wenn a=1
dann echo a ist 1
sonst echo a ist nicht 1
Im Grunde kann es Euch immer nützen, wenn Ihr regelmäßig umfangreiche Markierungen setzen müsst, nicht nur bei Markup im eigentlichen Sinne.
P.S.: Ach, bevor mir jemand mit Braucht keine Sau kommt (das ist meistens so): Die eigene Markup-Variante für Webseiten mit automatischer Übersetzung und Aktualisierung auf dem Server ist tatsächlich einer realen Arbeitssituation nachempfunden ;)


Ich stand gerade vollkommen auf dem Schlauch. Die Lösung ist doch ganz einfach. Hier ist sie für den fetten Text: sed ’s/**([^*^*]*)**/\\1\<\/b>/g‘. Nicht wirklich übersichtlich aber es funktioniert.
Joe
Danke für den super Artikel. Ich stehe gerade vor einem ähnlichen Problem, wirklich viele Textdateien von einer Markup-Variante in eine andere überführen zu dürfen. In diesen Texten kommen viele Zeilen in der Art: „Das ist ein Test Text mit viel fetter Auszeichnung.“ vor. Durch die gierige Interpretation der RegEx von sed, welche sich scheinbar nicht abstellen lässt, wird der Text stark verändert. Hast Du eine Tipp?
Danke Joe