Eine grundlegende inhaltliche Analyse von Dokumentenbeständen lässt sich unter Linux mit sehr einfachen Mitteln bewerkstelligen – die Häufigkeiten einzelner Schlagwörter geben fix Überblick über Schwerpunkte. Zudem ist es die perfekte Grundlage für Visualisierungen. Außerdem könnt Ihr bequem in relevanten Absätzen stöbern, ein wenig querlesen - ähnlich wie bei X-Ray beim Kindle.
Suche nach Schlagwörtern
Alle Absätze in Harry-Potter-Romanen, in denen Hagrid vorkommt anzeigen? Kein Problem. Alle Kapitel zum Thema Statistik in Lehrbüchern? Ganz fix. In einem einfachen Beispiel sollen alle Textdateien eines bestimmten Ordners nach diversen Schlagwörtern durchsucht werden, die anschließend nach Häufigkeit sortiert ausgegeben werden:
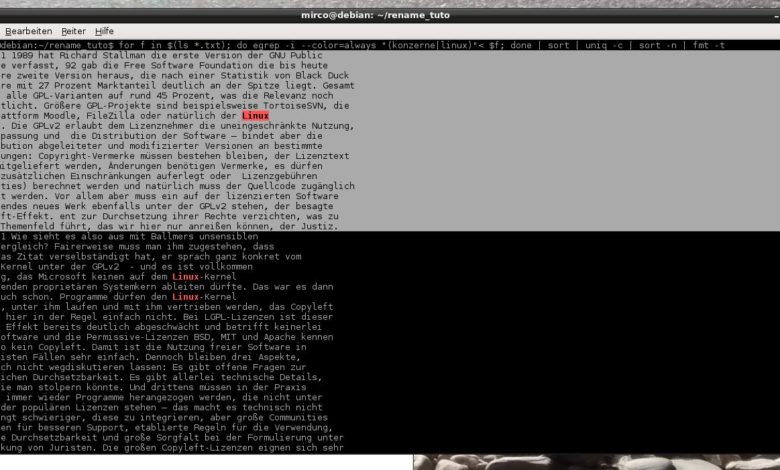
<code>$ for f in $(ls verzeichnis/*.txt); do egrep -io "(Linux|Windows|Android)"< $f; done | sort | uniq -c | sort -n </code>
Die for-Schleife sorgt schlichtweg dafür, dass jede einzelne TXT-Datei im Ordner „text“ vom folgenden egrep-Statement erfasst werden. Gesucht werden von egrep nur die einzelnen Vorkommen (via "-o") der angegebenen Betriebssysteme, egal, ob groß oder klein geschrieben (via "-i"). Die resultierende Wortliste wird nun erst mit sort sortiert, dann erkennt uniq nebeneinander liegende doppelte Zeilen/Wörter und gibt sie samt Anzahl aus – dank des zweiten sort-Befehls aufsteigend sortiert nach Häufigkeit.
egrep effizient einsetzen
Mit zwei kleinen Modifikationen erhaltet Ihr ein komplett anderes Ergebnis:
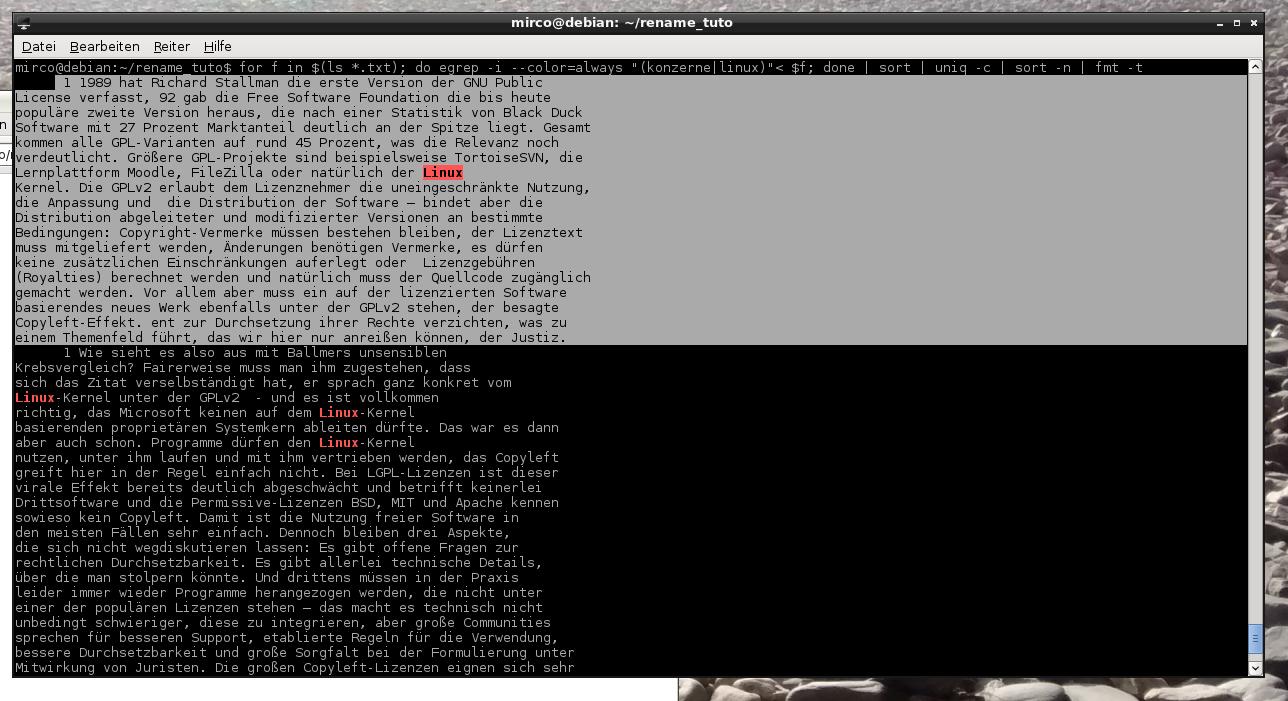
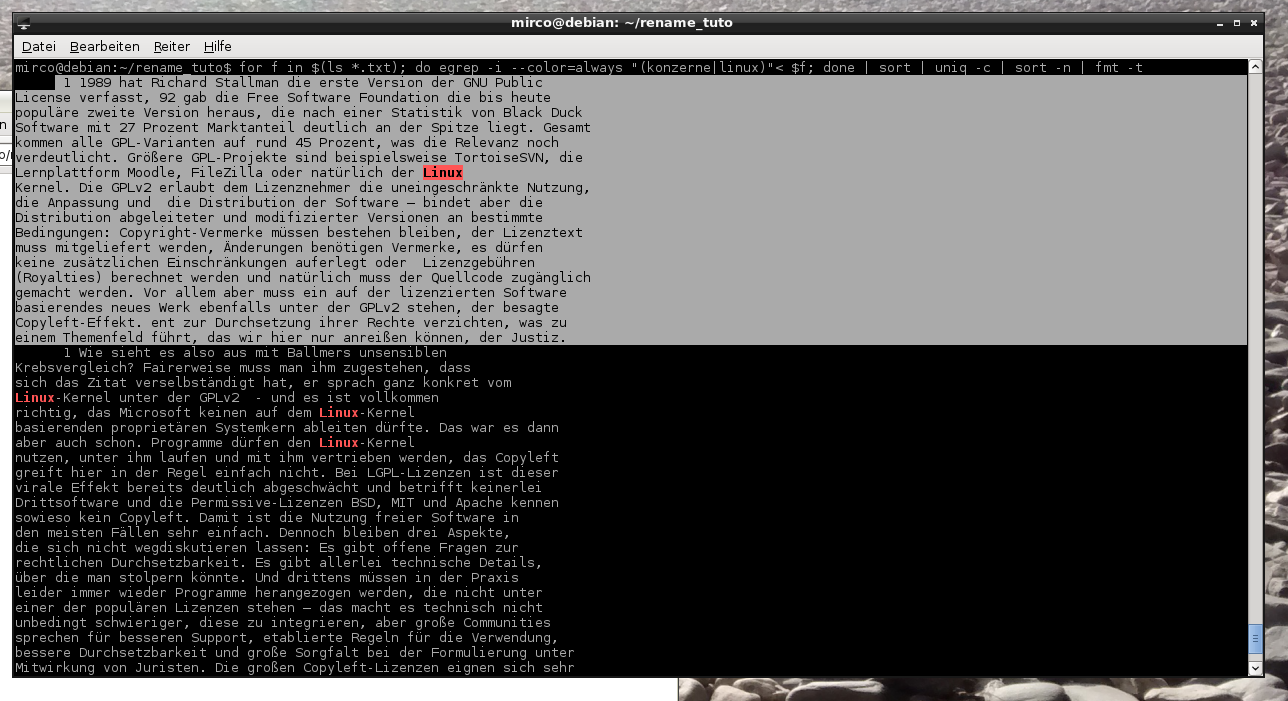
$ for f in $(ls verzeichnis/*.txt); do egrep -i --color=always "(Linux|Windows|Android)"< $f; done | sort | uniq -c | sort -n | fmt -t
Ohne die „-o“-Option gibt egrep nun nicht bloß den übereinstimmenden String aus, sondern jeweils die ganze Zeile, die den String enthält, also in der Regel Absätze – die durch das angehängte fmt gleichmäßig formatiert werden. Mittels „-t“ rückt fmt die ersten Zeilen der Absätze anders ein, sodass sich im Ergebnis gut stöbern lässt. Natürlich ließe sich das ganze auch anders lösen und ebenso natürlich könnten hier noch allerhand Verfeinerungen durchgeführt werden, aber um schnell mal in den Lehrmaterialien der letzten Semester zu stöbern oder Eure Lieblingsorte aus Romanen zu besuchen, genügt es allemal - TXT-Dateien vorausgesetzt, aber die lassen sich ja erstellen, etwa aus PDFs.
Übrigens: Mit den richtigen Tools geht das ganze natürlich auch unter Windows.