Onion-Adressen verschwinden leider alle Nase lang, daher seid Ihr sicher des öfteren mal über tote Verweise gestolptert. Durch die Umstellung auf ein neues Format wurden im vergangenen Jahr alle Links ungültig - und Tausende Blog-Beiträge somit obsolet. Diese Links alle zu aktualisieren ist recht aufwändig, weil die neuen Links für die alten Seiten erstmal gefunden werden wollen. In der Praxis dürfte das kaum ein Seitenbetreiber machen, wir haben zumindest die meisten Links auf das v3-Format aktualisiert. Aber die Umstellung war eine einmalige Angelegenheit, Onion-Seiten sind aber auch davon abgesehen meist weniger langlebig als man es aus dem WWW gewohnt ist. Also muss Automatisierung ran.
Monatlich aktualisiert?
Nach der v3-Aktualisierung habe ich einen neuen Artikel mit 50+ Darknet-Links angelegt: Besser für Euch, weil Ihr nicht erst ein halbes Dutzend kleiner Linklisten durchklicken müsst, besser für uns, weil es so deutlich einfacher ist, das Ganze aktuell zu halten. Im Titel steht auch monatlilch aktualisiert, was sofort den Kollegen auf den Plan rief, der diese Ansage für etwas wagemutig hielt - schließlich machen wir Tutonaut.de nicht in Vollzeit. Guter Einwand, gilt aber nur, wenn man des Scriptings nicht mächtig ist.
Händisch wäre das der Horror: 50 Links einzeln anzuklicken und einige zu aktualisieren mag nur ein Stündchen dauern, ist aber super lästig - und die Liste wächst! Spätestens bei 100 Links hätte da niemand mehr Lust zu.
Also muss ein Skript her, das alle Links automatisch prüft und Probleme meldet. Wichtig dabei: Die Links müssen aus dem Artikel gelesen werden, da dieser möglicherweise von mehreren Autoren gefüllt wird. Dann müssen die Links einzeln "besucht" und die Status ausgegeben werden. Und damit das nicht zu einfach wird: Natürlich sind Onion-Adressen nur via Tor erreichbar.
Der Onion-Prüfer
Im Grunde ist die Aufgabenstellung ziemlich simpel und dazu äußerst nützlich - und insofern ein hübsches Projekt für die Einführung ins Thema Scripting. Es soll Menschen geben, die die Kommandozeile für tot halten, weil Klickibunti doch sooo überlegen sei ... Nein, sie ist nicht tot.
Hier nochmal die einzelnen Aufgaben, die erledigt werden sollen, samt der zugehörigen Tools:
- Links aus Artikel extrahieren: curl, html2text, grep
- Links besuchen und Status ermitteln: torify, curl, grep, cut
- Status und Links ausgeben: test, echo
Das Ganze findet hier unter Linux in der Bash-Shell statt, unter Windows würde es aber natürlich auch funktionieren. Hier das Skript:
i=1
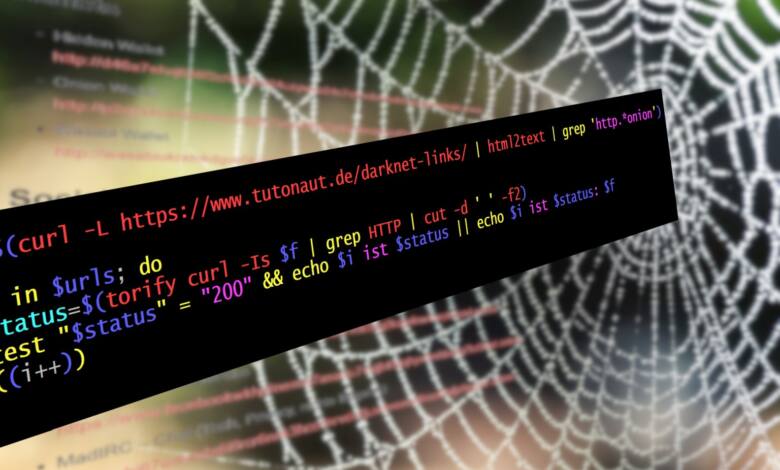
urls=$(curl -L https://www.tutonaut.de/darknet-links/ | html2text | grep 'http.*onion')
for f in $urls; do
status=$(torify curl -Is $f | grep HTTP | cut -d ' ' -f2)
test "$status" != "200" && echo $i ist $status: $f || echo $i ist $status
((i++))
done
Und hier ein Auszug aus der Ausgabe des Skripts:
14 ist 200
15 ist 405: http://wasabiukrxmkdgve5kynjztuovbg43uxcbcxn6y2okcrsg7gb6jdmbad.onion/
16 ist : http://dreadytofatroptsdj6io7l3xptbet6onoyno2yv7jicoxknyazubrad.onion/
200 heißt, dass alles in Ordnung ist - deshalb wird hier auch kein Link ausgegeben. Bei allen anderen oder fehlenden Status-Codes kommt der Link zum Prüfen. Für die Nummerierung vorne wird schlicht die Zählvariable $i ausgegeben, der Statuscode steckt in der Variablen $status und die URL in $f.
Wieder zum Skript. Zunmächst werden alle URLs als Liste in der Variablen $url gespeichert: curl besorgt den gesamten Artikel als HTML-Code, html2text wandelt diesen ins Textformat, grep extrahiert Zeilen, die mit http anfangen und mit onion enden. Das Ergebnis ist also eine Liste mit URLs, jede in einer eigenen Zeile, gespeichert in $urls.
Die for-Schleife läuft dann einfach für jede Zeile/jede URL in $urls durch, gibt die Status aus und zählt $i immer um 1 hoch. Die URLs landen also jeweils in der Variablen $f.
Die eigentlichen Infos kommen jetzt in die Variable $status: Der Kniff liegt hier bei torify, das zur Tor-Installation gehört und schlicht den Zugriff auf Onion-Seiten ermöglicht, so wie der Tor-Browser es auf grafischer Seite tut. Über curl -Is $f wird der Status abgefragt, wobei die curl-Optionen curl-eigene Statusmeldungen unterdrücken (-s für silent) und lediglich Metainformationen (-I) besorgen. grep HTTP filtert dann die eine Zeile mit dem HTTP-Status heraus und cut löscht alles aus dieser Zeile bis auf Feld 2. (Vor cut sieht die Ausgabe so aus: "HTTP/1.1 200 OK" - das sind 3 Felder/Spalten, getrennt durch Leerzeichen.)
test prüft dann, ob der Status nicht 200 ist und gibt dann Nummer ($i), Status ($status) und URL ($f) aus. Falls nicht (||), werden nur Nummer und Status ausgegeben.
Natürlich ließe sich hier noch herumfeilen, beispielsweise könnte man sich die Ausgabe der vielen 200er sparen, aber ich hätte gerne eine sichtbare Bestätigung. Auch könnte man andere Status-Codes abfragen, da zum Beispiel ein 405 nicht dazu führen würde, dass der Link verschwindet, da es sich um kurzfristige technische Probleme beim Server handeln könnte oder irgendwas mit der Tor-Verbindung nicht stimmt. In einer Größenordnung von 50 bis 100 Einträgen, und mehr werden es sicherlich nicht, genügt es aber so.
Zum Mitnehmen: Mit curl lässt sich so ziemlich alles aus dem Netz besorgen und mit Tools wie grep, cut, sed, trim und so weiter in die gewünschte Form bringen - womit das Tor zu spannenden Datenanalysen weit offen steht. Auch vollautomatisches Blogging ist damit möglich, wie ich bei Dev-Insider.de mal beschrieben habe.